Pomimo tych teoretycznych dyskusji, dzisiejsza rzeczywistość jest taka, że handel elektroniczny online jest zdominowany przez przeglądarkę internetową i protokoły internetowe. Sieć została po raz pierwszy opracowana jako narzędzie wspierające badania naukowe, zapewniając pracownikom naukowym, rozproszonym po całym świecie i połączonym z różnymi systemami komputerowymi, dostęp do dokumentów oraz komunikowanie się ze sobą niezawodnie i wydajnie, przy użyciu protokołów transmisji TCP /IP, jak wyjaśniono w części 2, Architektura systemów e-biznesu. Sieć to aplikacja (lub przynajmniej zestaw aplikacji), która działa w Internecie. Nie jest absolutnie konieczne uruchamianie aplikacji internetowych w Internecie i nie jest nieuniknione, że handel elektroniczny działa na jednym lub obu, chociaż oba stanowią, pojedynczo i razem, bardzo dobry przypadek. Rzeczywiście, dzisiaj jest to niezmiennie wybrana konfiguracja. Większość czytelników jest dobrze zaznajomiona z korzystaniem z Internetu w celu uzyskania dostępu do zdalnych serwerów w Internecie. Usługi sieciowe są świadczone za pośrednictwem standardowej architektury klient – serwer opisanej wcześniej: komputer użytkownika, stacja robocza lub ewentualnie cyfrowy dekoder jest wyposażony w oprogramowanie, przeglądarkę, która komunikuje się ze zdalnym serwerem sieciowym za pomocą jeden z zestawu protokołów aplikacji, z których najpopularniejsze to http dla ‘stron WWW’, smtp dla poczty elektronicznej, ftp dla dostępu do zdalnych plików. Zwróć uwagę, że Serwer WWW to oprogramowanie, a nie sprzęt (choć oczywiście może być hostowany na zarezerwowanym do tego celu komputerze). Największym zainteresowaniem w aplikacjach eShopping jest http, ponieważ jest to protokół używany do uzyskiwania dostępu do stron WWW na zdalnym serwerze, które wspólnie próbują stworzyć katalog wystawowy dla oferowanych towarów. Użytkownicy uzyskują dostęp do eShopu, wysyłając żądanie przeglądarki w postaci polecenia http. Polecenie: http://www.myshop.co.uk rozpoczyna się od zlokalizowania adresu IP odpowiadającego serwerowi WWW dla WWW.myshop.co.uk. W tym celu uzyskuje dostęp do serwera nazw domen (DNS), który został przypisany przez administrację systemu do (pod-)sieci, w której znajduje się komputer kliencki). Przykład tego, jak to działa, w przypadku kupującego w domu podłączonego do dostawcy usług internetowych .
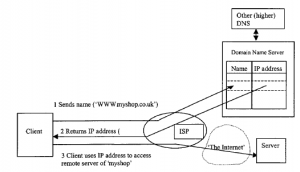
DNS utrzymuje tablicę przeglądową, która ustala korespondencję między (zwykle) niezapomnianą nazwą („www.myshop.co.uk”) a „prawdziwym” adresem internetowym („adres IP”) serwera zakupów. Jeśli sam nie zawiera tych danych, może przekazać żądanie do usługi DNS wyższego poziomu. Gdy nazwa zostanie powiązana z rzeczywistym adresem, klient może wysłać żądanie do serwera WWW. W tym przypadku, ponieważ nie wysłał żadnych dodatkowych poleceń w wiadomości http, w rzeczywistości prosi serwer o przesłanie swojej standardowej strony wejściowej. Jeśli żądanie się powiedzie, dokładnie to zrobi serwer: wyśle wiadomość zwrotną do przeglądarki, która z kolei wyświetli go na ekranie użytkownika. Wysłana wiadomość to strona internetowa, która dziś prawie we wszystkich przypadkach została skomponowana za pomocą hipertekstowego języka znaczników (HTML). Ogólnie rzecz biorąc, strona internetowa jest dokumentem, zwykle napisanym w języku HTML, przechowywanym w pliku, z którego można uzyskać dostęp przez Internet.
HTML jest znacznie uproszczoną wersją Standard Generalized Markup Language (SGML) [27], dość złożonego języka publikacji elektronicznych. To nie tylko określa układ dokumentów, ale pozwala na opisanie ich szczegółowej struktury, a nawet kontekstu w organizacji w sposób jednoznaczny i możliwy do przetworzenia przez maszyny. SMGL mógł kiedyś być potencjalnym kandydatem na język programowania używany do opisywania złożonych transakcji międzybranżowych, które omówimy w części 2. Jednak prawdopodobnie przegrał z raczej prostszym kandydatem, Extensible Markup Language, XML, który omówimy bardziej szczegółowo w Części 2, Zarządzanie wiedzą e-biznesową. Podobnie jak większość oprogramowania DTP, HTML otacza tekst, który ma być oglądany przez użytkownika, dodatkowymi metainformacjami, które dają dalsze instrukcje przeglądarce, która go wyświetla. Jeśli nie znasz tej koncepcji, dobrym pomysłem jest przyjrzenie się kilku konkretnym przykładom. Przykładem strony HTML jest sam domyślny ekran przeglądarki. Uruchom przeglądarkę. Następnie, aby wyświetlić kod źródłowy tego, co jest dla Ciebie widoczne, wybierz „źródło” z opcji „widok” na pasku narzędzi przeglądarki. Na przykład zrobienie tego podczas przeglądania strony wprowadzającej Internet Explorera spowoduje wyświetlenie następującego tekstu:
< h2 style = ‘‘font:8pt/11pt verdana; color:black” id =”ietext”>Internet Explorer< /h2 >
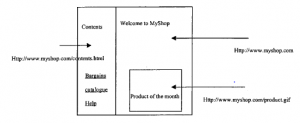
Ta linia odpowiada za wyświetlanie tekstu „Internet Explorer” jako „nagłówek typu 2” w kolorze czarnym. Zwróć uwagę, jak to się robi, włączając w to znaczniki rozdzielające ,h2…/h2, pomiędzy którymi operacja na tekście ma się zaczynać i kończyć. Początkowo HTML był używany głównie w Internecie jako medium do projektowania atrakcyjnych układów dokumentów tekstowych i nadal jest to jedna z jego głównych ról. Zapewnia udogodnienia dla różnych mocnych pozycji nagłówków, list numerowanych i nienumerowanych, tabel danych i tak dalej. Jednak być może najbardziej interesującą funkcją HTML jest możliwość dołączenia odnośnika http do innej strony internetowej – na przykład strona opisująca produkt może zawierać stwierdzenie takie jak „szczegóły”. Ta podkreślona nazwa to łącze, którego kliknięcie powoduje wysłanie żądania http do serwera kontrolującego ten plik w celu zwrócenia odpowiedniej strony. (Zgodność między słowem „szczegóły” a faktycznym adresem strony została wstawiona przez programistę i można ją ponownie zobaczyć, sprawdzając kod źródłowy.) Pierwotnie linki były rzeczywiście reprezentowane na stronie internetowej głównie jako element tekstu – wielu nadal tak jest – ale środowiska tworzenia stron internetowych pozwalają teraz średnio niewykwalifikowanym programistom na umieszczanie przycisku lub obrazu w celu reprezentowania łącza do przeglądarki. Rozwój przeglądarek obsługujących ramki był wczesnym rozszerzeniem możliwości wyświetlania pojedynczej strony HTML. Tutaj ekran może zostać podzielony na wiele obszarów, z których każdy może pomieścić osobny plik, którego rozmiar i położenie jest zgodne z główną stroną zestawu ramek, która rzeczywiście działa jak ramka, do której wstawiane są poszczególne strony. Zapewnia to, na przykład, bardzo wygodny sposób na ciągłe utrzymywanie paska narzędzi kontrolnych na ekranie, jednocześnie umożliwiając użytkownikowi przeglądanie wyników wyszukiwania katalogu produktów w pozostałej części ekranu