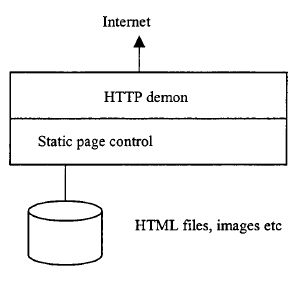
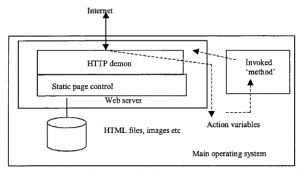
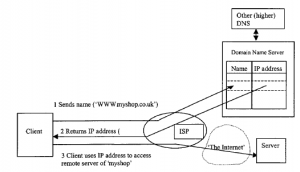
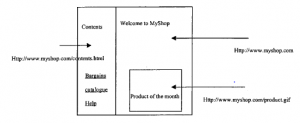
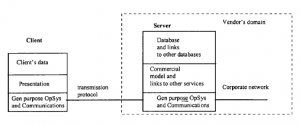
Pod wieloma względami najważniejszym elementem doświadczenia zakupowego jest platforma sprzedawcy, na której zamontowana jest większość oprogramowania eCommerce. Jak pokazuje rysunek,

platforma ta wygląda na dwa sposoby, w kierunku klienta i w biznesie. Platforma eCommerce jest raczej koncepcyjna niż rzeczywista. Jak zobaczymy, składa się on z części wielopoziomowej architektury komputerowej, zamontowanej na wielu platformach sprzętowych i programowych. Rzeczywiście, części modelu eCommerce będą czasami hostowane na terminalu klienta użytkownika, a nie tylko na serwerze dostawcy. Ale koncepcja platformy eCommerce jest jednak przydatna, ponieważ pozwala nam pomyśleć o niezbędnych elementach, które są potrzebne do obsługi eCommerce. W naszej dyskusji na temat zasad handlu elektronicznego wspomnieliśmy o zestawie wymagań DAVIC. DAVIC zmapował to również na podstawowy zestaw funkcji wykonywanych przez użytkownika końcowego, dostawcę usług, dostawcę treści i dostawcę sieci . Ich lista życzeń, pokazana w tabeli, zapewnia najwyższą specyfikację doświadczeń zakupowych i wyznacza dość wymagające cele dla programistów eCommerce, korzystających z istniejącej technologii.
Podstawowy zestaw funkcji DAVIC
Użytkownik końcowy
U1 Poruszaj się po środowisku zakupów
U2 Wybierz interesujące Cię pozycje
U3 Odbieranie (i) zdjęć przedmiotów, (ii) tekstu, (iii) dźwięku, (iv) ruchomego wideo, (v) nieruchomej i animowanej grafiki opisującej przedmioty
U4 Porozmawiaj z prawdziwym sprzedawcą (tylko audio lub audio wideo), który zna kontekst aplikacji (do rozważenia w przyszłości)
U5 Kontroluj klipy multimedialne, w tym powtórz, wstrzymaj i przerwij
U6 Autoryzuj płatność/zakup towarów
U7 Zapytanie i zmiana poprzedniego zakupu (zamówień), w tym żądanie autoryzacji wymiany/zwrotu
U8 Umiejętność wykonania kopii papierowej
U9 Rezerwuj produkty/usługi
U10 Wybierz metodę płatności
Dostawca usługi
S1 Zapewnij środowisko zakupów!
S2 Poproś o przesłanie klipów multimedialnych do użytkownika
S3 Wyślij klipy multimedialne do użytkownika
S4 Przetwarzaj pozycje zamówienia użytkownika
S5 Prowadź pośrednią listę nabytych
Dostawca treści
C1 Zapewnij klipy multimedialne do produktów
C2 Podaj informacje o cenie, dostępności, czasie dostawy, specjalnych warunkach
C3 Kategoryzacja materiałów do selekcji elektronicznej
C4 Określ układ sklepu wirtualnego
C5 Przypisz produkty do wirtualnych działów
Dostawca internetu
N1 Przesyła różne formaty danych do użytkownika, w tym: filmy, zdjęcia, dźwięk, tekst i grafikę
N2 Przesyłaj informacje od dostawców treści lub usługodawców na serwer w celu uzyskania szybkich aktualizacji informacji o produktach
N3 Zezwalaj na dynamiczne dodawanie/usuwanie połączeń między użytkownikiem końcowym a dodatkowymi serwerami (tj. jeśli użytkownik „kliknie” element, który ma klip wideo, wówczas musi być skonfigurowany „potok” wideo dla użytkownika)
Jak również powiedzieliśmy wcześniej, prawdziwe przykłady zakupów w Internecie zostały oparte na tym, co jest możliwe, być może stosunkowo łatwe do wdrożenia, a nie na liście DAVIC, która może, ale nie musi, zostać zrealizowana, gdy cyfrowa telewizja interaktywna stanie się usługą masową. Niemniej jednak warto zachować trochę pamięci na liście, aby porównać z tym, co faktycznie zostało osiągnięte.