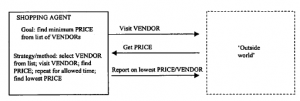
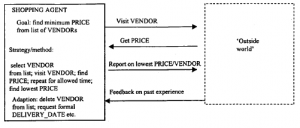
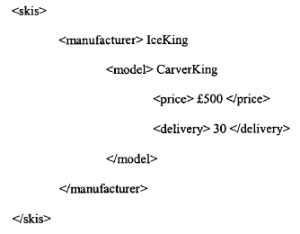
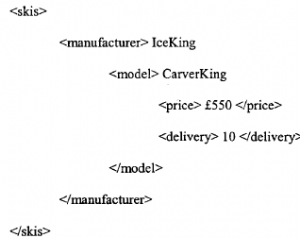
Często mówi się, że systemy transakcyjne on-line są uruchamiane przy użyciu sztucznych inteligentnych agentów, którzy będą negocjować między dostawcą a konsumentem. CORBA i inne podobnie rozproszone środowiska przetwarzania wyraźnie ujawniły modele obliczeniowe, w których scentralizowana kontrola nie jest już dominującym paradygmatem: procesy są uruchamiane tam, gdzie system decyduje, że mogą działać najlepiej, a decyzja ta jest podejmowana poprzez wymianę mocy obliczeniowej, a nie jej centralne przypisanie (patrz Część 2, Architektura systemów e-biznesowych). W zasadzie nie ma powodu, dla którego uprawnienia decyzyjne miałyby ograniczać się do wyboru platformy obliczeniowej lub algorytmu: moglibyśmy rozszerzyć zasadę o umożliwienie autonomicznym procesom podejmowania decyzji zakupowych dotyczących dóbr rzeczywistych. Oznacza to, że przenosimy koncepcje niezależnej, ale kooperacyjnej interakcji między komponentami oprogramowania pośredniego w DCOM, CORBA itp. do warstwy aplikacji, gdzie procesy współdzielące wspólne opisy aplikacji mogą działać na różnych platformach, dążąc do uzgodnionego rozwiązania tej aplikacji. Procesy zazwyczaj komunikują się i mogą obejmować transmisję samodzielnych modułów kodu z jednej platformy na drugą. Procesy te są czasami nazywane autonomicznymi lub inteligentnymi agentami oraz, gdzie mogą „wędrować” po sieci firmowej, agentów rozproszonych lub mobilnych. W koncepcji tych agentów jest coś raczej uwodzicielskiego: czasami wydają się posiadać nadludzkie (lub z pewnością superkomputerowe) zdolności negocjacyjne. Po prostu „wrzucamy” ich do sieci, uzbrojonych w prawo do negocjowania najniższej ceny produktu lub najlepszych warunków umowy na dostawę i z tym wracają. Rzeczywistość jest nieco inna, ale agenci handlowi są czymś więcej niż tylko pustym pojęciem i mogą z czasem stać się bardzo ważnymi elementami strategii e-biznesu. Przede wszystkim, kim jest agent handlowy? Rzeczywiście, kim jest agent? Próby były podejmowane z definicji, na przykład [132], ale najbezpieczniejszą odpowiedzią jest to, że nie ma prostej odpowiedzi. Termin ten był używany na tak wiele różnych, niespójnych sposobów, że definicja jednej osoby z pewnością obrazi kogoś innego. W obawie przed dodaniem do debaty, ale w interesie dalszego rozwoju, staramy się przynajmniej dać ogólne wrażenie na temat tego, czym jest i robi agent handlowy/negocjacyjny:
* Jest to fragment kodu, który wchodzi w interakcję z innymi fragmentami kodu, aby pomyślnie zakończyć zestaw transakcji, lub przerywa działanie bez awarii systemu, jeśli nie można tego zrobić.
* Zadowalające zakończenie transakcji osiąga się, gdy osiągnięty zostanie zestaw celów w ramach agenta oraz w innych procesach, z którymi współdziała.
Kodeks zawiera strategię, dzięki której działa, aby osiągnąć swoje cele.
* Próbując osiągnąć cel lub przynajmniej podcel, agent może podejmować pewne decyzje, być może dzieląc je z „obcymi” procesami, bez bycia kontrolowanym przez jakąkolwiek zewnętrzną, scentralizowaną funkcję kontrolną.
* Agent może modyfikować swoją strategię i być może swoje cele w świetle doświadczenia.
Biorąc pod uwagę te bardzo ludzkie cechy, łatwo jest zobaczyć, które agenty oprogramowania zostały poddane antropomorfizacji. Musimy bardzo uważać, aby nie pomylić listy życzeń z rzeczywistością. Istnieje szereg aspektów architektonicznych, które przede wszystkim odróżniają rozwiązania oparte na agentach od innych mechanizmów rozwiązania:
* Konstrukcja modułu agenta jest sformułowana parafialnie – nie ma szczegółowych założeń dotyczących globalnej architektury (dostawca platformy, optymalizacja zadań w innych lokalizacjach biznesowych itp.)
* Interakcja między jednym agentem a komplementarnym procesem lub agentem, z którym wchodzi w interakcje, opiera się na negocjacjach, a nie na operacji master-slave.
* Negocjacja opiera się na regułach i formatach interfejsu, które są znane wszystkim procesom współdziałającym.
* Wewnętrzne szczegóły dotyczące przebiegu tych negocjacji niekoniecznie są ujawniane.
* W wielu przypadkach instancje agentów mogą być tworzone bez ograniczeń, każdy utworzony w ten sposób agent jest odizolowany od innych, a jego jedyna interakcja z innymi odbywa się za pomocą wcześniej uzgodnionego protokołu przesyłania wiadomości.
* Ponieważ sposób, w jaki każda konkretna instancja rozwiązywania zadania zwykle zależy od złożonej interakcji kilku instancji agentów, z których każda działa w kierunku celów, które są oparte na ich bieżącym środowisku, zwykle nie jest możliwe (lub przynajmniej bardzo trudne) określenie kompaktowy globalny algorytm, który próbują rozwiązać. Zamiast tego rezultatem jest przykład zachowania emergentnego, które wynika z ich interakcji. Czasami do opisu tego zjawiska używa się terminów system samoorganizujący się lub koneksjonizm.
* Chociaż zdolność do adaptacji zachowania w świetle przeszłych doświadczeń nie ogranicza się wyłącznie do architektur agentów (a niektórzy agenci są nieadaptacyjni), metody osiągania tego poprzez modyfikację indywidualnych celów agentów są raczej specyficzne dla nich.
Z powyższego opisu może wynikać, że oparte na agentach systemy rzeczywiście wykazują duże podobieństwo do projektowania komponentów opartego na obiektach dla rozproszonych, heterogenicznych transakcji. Współdziałają za pośrednictwem określonych interfejsów, nie są zbyt dociekliwi, jeśli chodzi o wewnętrzne mechanizmy drugiej strony, pozwalają na wielokrotne tworzenie i izolowanie tych instancji i tak dalej. Rzeczywiście, do ich projektowania często używa się metod i języków obiektowych. Na bardziej szczegółowym poziomie czasami okazuje się, że klasyfikacja typów i zastosowań agentów jest sama w sobie dziedziną badań. Odnośnik [133] dostarcza jednej użytecznej taksonomii. Zgodnie z tym, i większością innych schematów, agenci e-biznesu są członkami klasy agentów spółdzielczych i mogą być dogodnie podzieleni według funkcji na zleceniodawcę, dostawcę lub agenta maklerskiego, w zależności od tego, czy ich główną funkcją jest wyszukiwanie/konsumpcja informacji lub usług reklamować i świadczyć te usługi lub „dopasowywać” lub „pośredniczyć” między pozostałymi dwiema klasami. Interesujące jest to, że ta taksonomia sugeruje, że zawsze będzie istniał związek asymetryczny, prawdopodobnie odzwierciedlający prawa umów. Być może dlatego pouczające jest myślenie o agentach jako procesach, które negocjują zasoby, bezpośrednio lub za pośrednictwem innych agentów. Jeśli tak jest, to możemy poszukać procesów biznesowych, które mają ten „umowny” charakter i uznać je za oczywistych kandydatów do systemów agentowych. Wśród nich są oczywiste kandydatury, w tym pojedynczy zakup przez klienta, negocjacje kontraktów międzybranżowych o dostawę i odwołanie, a także, w dość innym obszarze, harmonogramowanie prac w środowisku wieloproduktowym i wieloliniowym.