Pozostaje problem sprawdzenia zawartości rzeczywistego koszyka zakupowego klienta lub równoważnie zawartości kartonu, który został odebrany przez agenta w firmie logistycznej. Kontrola wizualna jest metodą tradycyjną, ale jest obarczona błędami, a obecnie najczęstszym sposobem jest użycie jakiejś formy automatycznego sprzętu skanującego, zarówno przy kasie, jak i w pakowalniach obsługujących handel elektroniczny. Najwcześniejszym tego typu systemem jest kodowanie kreskowe, które zostało pierwotnie opracowane w latach 50. XX wieku, aby zaspokoić potrzeby kolei amerykańskich w dążeniu do prowadzenia ewidencji ich wagonów towarowych. Kodowanie kreskowe wydaje się zwodniczo proste, ale w rzeczywistości podlega wielu różnym standardom (jedno źródło podaje aż 225) i wymaga pewnych dość ścisłych technologii do jego niezawodnego działania. Wspomnieliśmy, że przynajmniej teoretycznie dostępna jest duża liczba kodów kreskowych. Chociaż niektóre z nich mogą uzasadnić swoje istnienie jedynie przypadkiem, być może poprzez wczesne przyjęcie zastrzeżonego standardu, istnieją również prawdziwe powody, dla których nie ma jednego dominującego kodu. Formaty kodów kreskowych są kompromisem w stosunku do sprzecznych wymagań, głównie między rozmiarem a niezawodnością i/lub możliwościami kodowania. To, co jest możliwe z boku dużego kartonu, może nie być możliwe z boku małego opakowania. Nawet po wybraniu odpowiedniego standardu pojawiają się inne kompromisy: należy zastanowić się, czy użyć kompleksowego kodu, który jednoznacznie identyfikuje producenta, kraj pochodzenia itp., czy też krótszej wersji wykorzystującej ten sam schemat kodowania, ale wyświetlającej tylko numer części bez dalszych szczegółów pochodzenia. Jest to zadanie modelowania danych, które musi uwzględniać możliwe relacje handlowe i wszelkie plany ekspansji zagranicznej, które firma może mieć na uwadze, ponieważ unikalność może zostać utracona, jeśli kody zostaną w ten sposób skrócone. (Jedną ze strategii, którą można zastosować, jest podzielenie kodu na składniki „opakowania”: na przykład część kodu może znajdować się na drewnianej palecie, na której towary są obsługiwane luzem, a pozostała część kodu znajduje się na tymczasowej etykiecie na kartonie zamówienia klienta.Istnieje ograniczona liczba sposobów, w jakie możemy wykorzystać kod kreskowy do przedstawienia danych.
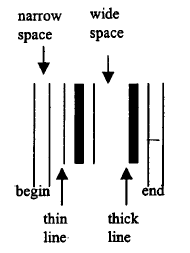
Mając na uwadze, że skanowanie kodu można wykonać ręcznie, z dowolną prędkością, a wydruk kodów można wykonać w różnych skalach, najlepiej jest używać miar względnych do reprezentowania danych. Odbywa się to w kategoriach „grubych” i „cienkich” linii (oraz, w niektórych kodach, spacji).Zakłada się, że prędkość skanowania będzie w miarę stała podczas jednej operacji, aby te różnice były wykrywalne. Niektóre kody mają linie początkowe i końcowe, jak pokazano, a niektóre wykorzystują cyfry kontrolne. Przechodząc do określonych standardów kodów kreskowych, można znacznie zmniejszyć liczbę 225 typów wspomnianych powyżej w bardzo wielu mniejszych liczbach, przynajmniej w przypadku handlu w całym przedsiębiorstwie. Amerykański standard kodów kreskowych UPC wersja A był prawdopodobnie pierwszym, który osiągnął szerokie uznanie i jest nadal powszechnie stosowany. W połowie lat 70. Europejskie Stowarzyszenie Numeracji Artykułów stworzyło standard EAN, którego dzisiejszą wersją jest EAN-13. Oba te kody są wyłącznie numeryczne i mają ustaloną długość danych oraz cyfry kontrolne zwiększające wiarygodność. Są to kody, które widzimy na co dzień, na przykład na opakowaniach żywności i są używane głównie do obsługi kas i wewnętrznych operacji magazynowych. Chociaż ten format jest kompaktowy i łatwy do uzgodnienia i wdrożenia, nie jest wystarczająco elastyczny dla wielu innych zastosowań, takich jak śledzenie dystrybucji, pakowanie i kontrola zapasów. Code 39 lub Code 3 of 9, jak jest czasami nazywany, jest zwykle preferowany do tych celów. Ma zmienną długość, jest tolerancyjny w szerokim zakresie rozmiarów i proporcji oraz posiada funkcje alfanumeryczne, co czyni go przydatnym, gdy powiązany tekst drukowany musi być interpretowany ręcznie. Jeśli problemem jest gęstość danych w kodzie kreskowym, jednym z rozwiązań jest użycie dwuwymiarowego kodu kreskowego. Spośród wszystkich kodów dwuwymiarowych najczęstszymi przykładami są PDF 417 i Maxicode. PDF 417 ma imponującą pojemność do 1 KB danych w jednym bloku kodowania. Można to wykorzystać na przykład do stworzenia etykiety kodującej zamówienie klienta, którą można przykleić do kartonu, do którego towar jest następnie pobierany przez operatora, który po prostu skanuje etykietę w punkcie kompletacji. Wybór towarów jest zatem możliwy bez konieczności powiązania numeru referencyjnego klienta z wyszczególnioną listą, co eliminuje potrzebę połączenia sieciowego między magazynem a działem zamówień. Ma to pewne zalety, gdy realizacja jest zlecana na zewnątrz (choć całkowita izolacja systemu magazynowego i zamówień nie jest najlepszym pomysłem). Przypisywanie konkretnych numerów kodowych firmom i produktom jest nadzorowane przez odpowiednie organy kodowania numerów, takie jak EAN. Z pewnymi wyjątkami (głównie tam, gdzie towary są bardzo małe i wymagają skróconego kodowania), przypisanie numerów do produktów pozostawia się samej firmie, organ regulujący po prostu przydziela numer firmy i kod kraju organu przypisującego (nie firmy ).