Obiektowe podejście do projektowania i kodowania oprogramowania nie zostało pierwotnie opracowane dla przetwarzania rozproszonego, ale okazuje się, że ma pewne zalety w tym kierunku. Projektowanie zorientowane obiektowo zaczyna się od zdefiniowania elementów, którymi chcemy manipulować, ich właściwości i sposobu, w jaki się ze sobą komunikują, w kategoriach wysokiego poziomu, a nie struktur danych i sposobu, w jaki komputery radzą sobie z danymi. „rzeczą” może być klient, konto itp.; oczywiste właściwości to nazwiska, adresy. Poszczególne rzeczy mogą należeć do wspólnej grupy, „klasy” i mieć wspólne właściwości, np. kobiety i mężczyźni należą do klasy ludzi i dzielą jedną z jej właściwości – wiek. Jest to jeden z powodów, dla których projektowanie zorientowane obiektowo jest istotne dla przetwarzania rozproszonego: pozwala nam zachować podstawowe koncepcje w oderwaniu od zdarzeń incydentalnych i przejściowych. Klienci są klientami i zachowują swoje szczególne właściwości bez względu na to, czy ich zakupy są odczytywane przez terminal kasowy w sklepie, czy też dokonywane za pomocą domowego komputera. Z drugiej strony „rabat branżowy” jest własnością środka zakupu, a nie konkretnego klienta, który go kupuje. W środowisku rozproszonym często chcemy ukryć położenie geograficzne usługi, ponieważ nie jest to istotne dla wymagań, a geografia rozprasza. Ta technika abstrakcji, w której podstawowe właściwości procesów są izolowane od sedna sprawy, ma wyraźną wartość w koncepcyjnym modelowaniu procesów biznesowych. Ale jest to co najmniej równie cenne również w domenie wdrożeniowej, gdzie często nie chcemy rozróżniać przetwarzania lokalnego i zdalnego, a nawet tego, czy proces działa na jednej czy na wielu maszynach. Jak powiedzieliśmy, przedmioty to nie tylko „rzeczy” w sensie fizycznym. Weźmy przykład „poborcy podatku od wartości dodanej” (TAXG). Programiści aplikacji, którzy chcą korzystać z TAXG, nie muszą wiedzieć, jak to działa, ale musisz wiedzieć o tym kilka rzeczy
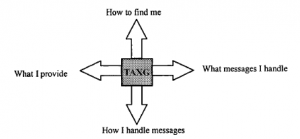
TAXG to „czarna skrzynka”, którą w całości definiuje:
† Usługi, które zapewnia aplikacjom.
† Sposób, w jaki aplikacje powinny wysyłać do niego wiadomości.
† Zestaw szczegółowych informacji na temat obsługi komunikacji, których aplikacje nie muszą znać, ale które mają na celu poinformowanie podstawowej infrastruktury rozproszonej.
† Unikalny identyfikator, który zostanie użyty do jego zlokalizowania, nawet jeśli będzie przemieszczał się z miejsca na miejsce. (Możliwe, że obiekt, który oblicza Twój podatek, może przenieść się z jednego komputera na drugi. Nadal chcesz uzyskać dostęp do tego, a nie tego, który rozlicza podatek kogoś innego lub wykonuje obliczenia na innej podstawie.)
W programowaniu obiektowym obiekty są definiowane przez definicje klas. Jest to sposób na zdefiniowanie „szablonu” dla obiektu, który obejmuje określenie jego właściwości (na przykład obiekt rachunku bankowego może mieć właściwości salda, nazwy i numeru rachunku) oraz kilka procedur lub metod, które umożliwiają m.in. właściwości, którymi należy manipulować. Za każdym razem, gdy tworzona jest nowa instancja obiektu (na przykład nowa osoba otrzymuje konto bankowe), ta instancja „bank_account_object” jest tworzona i zarządzana w pamięci komputera w ramach kompilacji, ładowania i uruchamiania obiektu zorientowany język programowania (C++, ActiveX, Java itp.), bez konieczności zajmowania się szczegółami. Zauważ, że jednym z aspektów generowania klas jest możliwość włączania lub dziedziczenia właściwości innych obiektów. (Na przykład klasy „mężczyzna” i „kobieta” mogą dziedziczyć po klasie „pracownik”). Uważa się, że jest to pomoc w szybkości i dokładności rozwoju. Jednak w przypadku stosowania orientacji obiektowej w systemach rozproszonych właściwość dziedziczenia nie wydaje się być szczególnie istotna. Jednym z aspektów podejścia zorientowanego obiektowo, które ma znaczenie dla systemów rozproszonych, jest to, że sprawia ono, że programowanie jest zadaniem dwuetapowym. Najpierw definiujemy strukturę każdego obiektu. Następnie „po prostu” piszemy resztę programu mniej więcej jako serię komunikacji między obiektami, używając dobrze zdefiniowanych reguł, które wychodzą ze sposobu, w jaki obiekty zostały określone. Często pożądane jest doprowadzenie tego podejścia do enkapsulacji do skrajności, ponieważ komunikujące się komponenty nie muszą nawet być świadome języka programowania, w którym napisane jest drugie. Tworzenie i zarządzanie obiektami stwarza pewne nowe problemy w przypadku rozproszonym: tworzenie nowej instancji obiektu może być inicjowane przez platformę kliencką zdalną z serwera, na którym ma zostać utworzona instancja. Należy zapewnić standardowe procedury tworzenia tych instancji w fabrykach obiektów. Podobnie rozproszone urządzenia muszą być dostępne do usuwania tych wystąpień, gdy nie są już potrzebne. Zwykle ukryty przed programistą aplikacji, musi też istnieć niezawodny sposób przesyłania danych pomiędzy rozproszonymi obiektami. Podsumowując, przejście od programowania obiektowego do projektowania komponentów wydaje się wiązać ze znaczącą zmianą w perspektywach. Najlepiej nie pytać, jakie są komponenty; lepiej opisać, co robią i jak się pojawiają, ponieważ można je realizować na różne sposoby, niekoniecznie obiektowe. Po pierwsze, ich wygląd: widziane z innych platform w systemie rozproszonym, widoczne są tylko przez ich interfejsy. Sposób implementacji komponentu na platformie hosta nie ma znaczenia dla reszty systemu
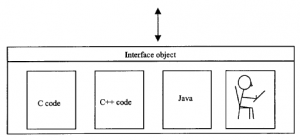
W dość fantazyjnym modelu pokazanym na, komponent wchodzi w interakcję ze światem poprzez całkowicie izolujący interfejs. Komputer kliencki uzyskujący dostęp do komponentu nie musi wiedzieć – i nie może powiedzieć – czy jest napisany w C, C++, Javie czy nawet wdrożony jako urzędnik księgi ludzkiej. Zaleta tego podejścia jest prosta: możliwość podłączania, możliwość łączenia procesów ze sobą bez martwienia się o ich wewnętrzne działanie. Wspomnieliśmy już o innej właściwości komponentów: niezależności ich lokalizacji. Chyba że trzeba wiedzieć, gdzie znajduje się składnik , gdzie jest zlokalizowany, jest to niepotrzebne rozproszenie uwagi. Ponownie, podstawową zasadą jest ukrywanie rzeczy przed projektantem, w tym przypadku miejsca pobytu komponentu. Ale jeśli nasze komponenty mają być uwolnione od wścibskich oczu programistów aplikacji, muszą nadal znajdować się pod kontrolą szeregu usług zarządzania, które same w sobie są niewidoczne dla programisty.
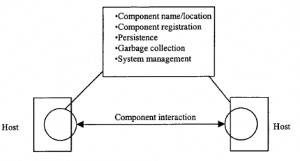
System zarządzania zawiera informacje o tym, gdzie znajdują się komponenty i jak się nazywają. Może zatem powiązać nazwę używaną przez programistę z rzeczywistym komponentem. Prowadzi również rejestr ważnych komponentów i podobnie listę osób, które mają do nich dostęp. Ponieważ obiekty będą często dystrybuowane, pewien nadrzędny proces musi być również odpowiedzialny za przechowywanie bieżących wartości stanów obiektów w magazynie trwałym, który może zapewnić odzyskiwanie danych dla hostów, na przykład w przypadku niepowodzenia transakcji. (Przetwarzanie transakcji jest opisane w dalszej części). I odwrotnie, gdy klienci nie używają już obiektów, musi istnieć pewne wyrzucanie elementów bezużytecznych, dzięki którym można zwolnić pamięć i rekordy stanu używane do przechowywania nadmiarowych wystąpień tych obiektów do nowego użytku. Wreszcie będzie zestaw ogólnych usług zarządzania do obsługi bezpieczeństwa i zarządzania zasobami. W różnym stopniu iz różnym powodzeniem, systemy zarządzania próbują radzić sobie z odpornością na błędy, równoważeniem obciążenia itp. Rozwiązania komponentowego oprogramowania pośredniczącego mają zwykle swoje korzenie w podejściu programowania obiektowego lub rozproszonego. Pritchard zapewnia przydatne rozróżnienie między architekturami komponentowymi, które koncentrują się na pakowaniu kodu i jego funkcjonalności w wielu językach, a architekturami zdalnymi, które dotyczą używania rozproszonych obiektów do uruchamiania zdalnych procesów. W tabeli 1.1 próbujemy umieścić kilka popularnych produktów oprogramowania pośredniczącego. DCOM firmy Microsoft rozszerza ideę komponentów w ramach pojedynczego komputera (zazwyczaj PC z systemem Windows), który został opracowany pod nazwą COM, na środowisko rozproszone, w szczególności na architekturę klient-serwer systemu Windows. CORBA i Java RMI to „systemy otwarte”. CORBA jest bardziej dojrzała i ma większy udział w rynku, ale Java RMI cieszy się dużym zainteresowaniem.