W naszej dyskusji na temat potrzeb, identyfikacji, kompetencji i elementów dowodowych modelu zaufania NICE wspomnieliśmy o pozytywnej roli, jaką może odegrać zaangażowanie stron trzecich, które zobowiązują się do własnej wiarygodności, działając jako gwaranty relacji. W ich interesie nie leży wspieranie organizacji, która nie wywiązuje się ze swoich obowiązków. W związku z tym klienci mogą ufać firmom, które popierają. Jeśli chodzi o model NICE, jeśli są dobrze znani, z doświadczeniem, mogą zastąpić ryzyko radzenia sobie z nieznanym wcześniejszymi dowodami ich własnych osiągnięć i kompetencji. W niektórych przypadkach, szczególnie gdy strona trzecia jest celebracją lub firmą zajmującą się stylem życia, możemy nawet identyfikować się z celami strony trzeciej i chcieć kupić to, co promują. Jednym szczególnie dobrym przykładem sposobu rozwijania identyfikacji między klientem a dostawcą za pośrednictwem poręczyciela będącego stroną trzecią jest usługa ratingowa. Nawet przed rozpoczęciem interakcji zakupowej ze sprzedawcą klienci czasami chcą się upewnić, że nie wchodzą w coś, czego mogliby później żałować. Szczególnym przypadkiem są kwestie gustu, na przykład definicja „przyzwoitości”. Sieć jest międzynarodowa i łatwa do publikowania. Oznacza to, że zawiera znaczną ilość materiałów, które mogą być uznane za obraźliwe dla wielu osób i kultur. Jak możemy być pewni, że znajdziemy materiał, który zgodnie z naszą definicją odpowiedni dla nas lub naszych dzieci do oglądania? Jednym ze sposobów podejścia do problemu jest przyjęcie polityki „buyer beware”, ale zapewnienie narzędzi, które utrudniają przypadkowe otrzymanie nieodpowiednich materiałów. Inicjatywa Platform for Internet Content Selection (PICS) została powołana w sierpniu 1995 roku przez przedstawicieli dwudziestu trzech firm oraz organizacje zrzeszone pod auspicjami konsorcjum MIT’sWorldWideWeb Consortium w celu omówienia potrzeby oznaczania treści. Ideą PICS jest zapewnienie sposobu, w jaki producenci treści i strony trzecie, takie jak czasopisma, organizacje konsumenckie i organizacje nadzorujące branżę, mogą wstawiać informacje do zasobów treści World Wide Web, przy użyciu standardowych protokołów, które można odczytać i podjąć odpowiednie działania. automatycznie przez komputery, aby zapewnić lokalną selekcję obraźliwych materiałów (i faktycznie wybór pożądanych treści) bez wprowadzania globalnej cenzury. PICS zależało na ustaleniu jedynie konwencji dotyczących formatów etykiet i metod dystrybucji, a nie słownika etykiet ani tego, kto powinien je nadzorować. Nacisk kładziony jest na wolność wyboru. Chociaż etykiety mogą być tworzone zgodnie z, na przykład, kategoriami oceny filmów („PG” itp.), przyjmuje się, że osobiste standardy i nastawienie muszą się różnić, szczególnie w kontekście globalnym. W każdym razie wydawcy mogą obejść te klasyfikacje, publikując w krajach, w których standardy są różne. (Nie chodzi tylko o ogólną swobodę: niektóre grupy społeczne są bardzo przeciwne przemocy, ale tolerują materiały o charakterze jednoznacznie seksualnym, w innych jest odwrotnie). Chociaż istniało wiele takich systemów oceny, PICS stara się ujednolicić podejście tak, aby było niezależne od dostawcy, a etykietowanie mogło być wykonane przez dowolną liczbę stron trzecich. Rzeczywiście, dowolna liczba organizacji etykietujących może w dowolnym momencie oznaczyć stronę.
Po lewej stronie tabeli podajemy przykład prostej etykiety PICS. Jeśli ktoś odwiedzi witrynę usługi etykietowania „http://www.here.-co.uk”, można oczekiwać wyjaśnienia, w jaki sposób powstała ta ocena, jak pokazano po prawej stronie stół
Etykieta: Wyjaśnienie
(PICS-1.0 „http://www.here.co.uk” etykiety „1998.01.01” do „1999.01.01” dla „http://www.newtv.uk.co/film.html” przez „ Oceny Bill Whyte (12 s 1 v 4)): Najpierw etykieta identyfikuje adres URL usługi etykietowania oraz podaje daty rozpoczęcia i zakończenia, w których etykietowanie jest ważne. Następnie podaje adres URL strony, która jest oznaczona i, opcjonalnie, kto ją oznaczył. Wreszcie podaje ocenę (język = 1, sceny erotyczne = 2, przemoc = 4)
Jak powiedzieliśmy, usługa etykietowania może robić to, co lubi. Nie musi ograniczać się do osądów moralnych. W rzeczywistości wcale nie musi oceniać stron z moralnego punktu widzenia. Może wybrać ocenę stron z przepisami na podstawie tego, jak kosztowny według niego był przepis, a nawet pikantność potrawy. Użytkownik usługi ustawia oprogramowanie filtrujące na swoim komputerze, aby wybrać żądaną ocenę. Usługa oceny, którą wybraliby, zależałaby od wiarygodności usługi dla nich: wegetarianie prawdopodobnie nie skorzystaliby z usługi oceny żywności zapewnianej przez stowarzyszenie marketingu wołowiny; Baptyści mogliby wybrać usługę oceny filmów oferowaną przez organizację o powiązaniach religijnych, podczas gdy humaniści prawdopodobnie by tego nie zrobili. Możliwe jest nawet umieszczenie na stronach filtra pory dnia: filtr PICS na serwerze w szkole mógłby zapewnić, że w okresie samokształcenia uczniowie będą mieli dostęp tylko do materiałów odpowiednich do tego, do czego powinni. studiować.
Jeśli chodzi o zarządzanie, dystrybucję i kontrolę etykiet, dwa mogą pojawić się pytania, w jaki sposób upewniamy się, że etykieta PICS zakrywa materiał, do którego jest przymocowana; skąd wiemy, że etykieta została nałożona przez deklarowaną agencję etykietującą? Prostym sposobem jest uzyskanie dostępu do informacji za pośrednictwem renomowanego usługodawcy, który podejmie kroki w celu zapewnienia, że materiał na serwerze nie jest udostępniany pod fałszywym pretekstem. Jeszcze większą gwarancję można uzyskać dzięki dwóm innym cechom PICS: jedną jest możliwość naniesienia na materiał „znaku wodnego”, na przykład w postaci funkcji haszującej (patrz strona 261). Dołącza to do tekstu zaszyfrowane podsumowanie strony, którego nie można łatwo zinterpretować ani uszkodzić przez złośliwy proces. Ponadto istnieje również możliwość umieszczenia na stronie podpisu cyfrowego organu odpowiedzialnego za oznakowanie. Istnieje wiele sposobów stosowania i filtrowania etykiet PICS .
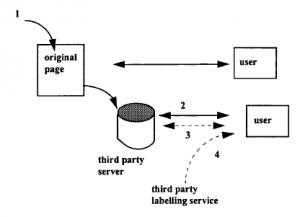
Na przykład autor strony może wstawić etykietę jako metatag HTML lub XML. Następnie przeglądarka użytkownika może je odczytać i zaakceptować lub odrzucić zgodnie z profilami skonfigurowanymi w przeglądarce. Alternatywnie serwer pośredniczący, prawdopodobnie obsługiwany przez niezależną stronę trzecią, może zostać poproszony przez przeglądarkę użytkownika o dostarczenie etykiet wraz z dokumentem. Rozszerzeniem jest to, że serwer pośredniczący może dostarczać użytkownikom strony, które wstępnie przefiltrował, aby oszczędzić im tego problemu. Klient mógł skorzystać z niezależnego biura etykietującego, które dostarczało jedynie etykiety. Zasadniczo ta firma tworzy selektywne filtrowanie, oparte na osądach wartościujących oceniających, krytyków itp. Te etykiety stron trzecich są „pieczęciami aprobaty”, a producenci treści mogą zapłacić, aby ich produkty zostały ocenione przez wiodące marki organów zajmujących się oznakowaniem. (Hipotetycznie pieczęci przyznawane obecnie niektórym producentom mogą być równoznaczne z treściami online oznaczonymi na przykład „nagrodą królewską”!) Można nawet wyobrazić sobie demokratyczną usługę etykietowania, w której użytkownicy uzyskujący dostęp do witryn indywidualnie oceniają materiał , z którego można by użyć średniego zestawu danych do wygenerowania zestawu zredukowanego.