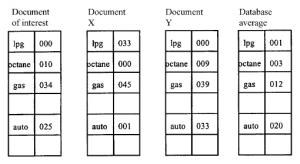
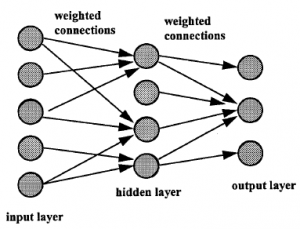
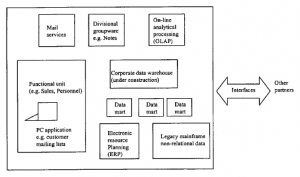
Zasady opisane do tej pory dotyczyły zachowania poszczególnych słów lub statystycznego związku między słowami, ale bez próby ich gramatycznego powiązania. Nieco bardziej ambitnym podejściem jest wykorzystanie podstawowej właściwości języka: posiadania gramatyki. NLP to wielki tytuł, który można zastosować do dość prostych procesów operujących na wolnym tekście, wykorzystującym podstawowe zasady. Ogólnie rzecz biorąc, oczekujemy, że silnik NLP będzie składał się z dwóch części: leksykonu, który zawiera listę słów, ich „znaczenie” w pewnym sensie oraz ich część wartości mowy (rzeczownik, czasownik itp.) razem ze składnią, zestawem reguł operujących na elementach leksykonu w celu wygenerowania „poprawnych gramatycznie” i „znaczących” fraz i zdań. Aby podać bardzo prosty przykład, leksykon może zawierać:

a regułą może być liczba mnoga ,x. ¼ ,x. 1 „s”. W praktyce prawdziwa gramatyka byłaby bardziej złożona. (Mógłby na przykład poradzić sobie z faktem, że liczba mnoga od „owce” nadal brzmiała „owce”, a nie „owce”, jak sugeruje nasz przykład). Niemniej jednak nawet ten prosty przykład ma pewną moc. Zauważ, że dla części mowy psa podane są trzy możliwości: „dobry pies” (rzeczownik), „dogonić czyjeś ślady” (czasownik), „róża psa” (przymiotnik) i prawdopodobieństwa ich wystąpienia są podane w nawiasach, w oparciu o pomiary w dużej liczbie tekstów, których części mowy zostały oznaczone przez ludzi. Można również gromadzić inne statystyki dotyczące słów i klas słów, na przykład części mowy, i umieszczać je w regułach statystycznych. Na przykład bardzo rzadko słowo „to” pojawia się bezpośrednio przed rzeczownikiem, ale bardzo często przed czasownikiem. Tak więc, ponieważ „pies” dość często występuje jako czasownik (15%), bardzo prawdopodobne jest, że będzie to słowo „piesić czyjeś ślady”.
Porównywalnie proste gramatyki NLP tego typu zostały użyte do analizy danych biznesowych, aby umożliwić bardzo dokładne wyodrębnienie nazw firm, lokalizacji itp. oraz analizę wiadomości e-mail w celu ustalenia, czy są to skargi. Dość inną aplikacją jest parsowanie zapytań wprowadzanych do wyszukiwarki, która odpytuje bazę danych. W tym przypadku parser wykorzystuje techniki NPL, aby poprawić wszelkie błędy popełnione przez osobę tworzącą zapytanie. Parser wykorzystuje gramatykę, która pozwala mu sprawdzić, czy zapytania mają poprawną strukturę i słownictwo, a także może posiadać wiedzę semantyczną o bazie danych, która umożliwia dalszą interpretację. Jednym z przykładów podanych przez jednego sprzedawcę jest parsowanie „6 Pak 12oz Diet Cola”, gdzie twierdzi się, że wiedza semantyczna jest wymagana do oddzielenia rozmiaru butelki od opakowania.