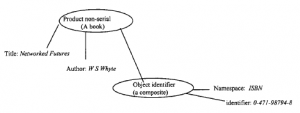
Dobre organizacje gromadzą dane w celu prowadzenia działalności, ale także do przyszłych analiz, aby kierować ich strategią. Logiczna (nie fizyczna) integracja tych danych w pojedynczą, zarządzalną przestrzeń informacyjną, zwłaszcza tam, gdzie ma to na celu wspieranie podejmowania decyzji zarządczych, nazywana jest hurtownią danych. Hurtownia danych to podejście koncepcyjne, a nie rzecz fizyczna, której celem jest integracja wielu rzeczywistych baz danych, które mogą być montowane na heterogenicznym zbiorze platform sprzętowych i programowych, zwykle rozproszonych. W poprzednim rozdziale omówiliśmy ogólny przypadek technicznej integracji takich systemów, odnosząc się do architektur komponentów i potrzeby interpretacji między bazami danych, od niskopoziomowych formatów danych po wysokopoziomową semantykę danych. Omówimy tutaj głównie technologie oparte na aplikacjach, które leżą na nich. Projektując hurtownię danych, należy podjąć decyzję, czy ma ona być zorientowana na dane, czy na aplikacje. W pierwszym przypadku model danych dla hurtowni jest zaprojektowany (w miarę możliwości) tak, aby był niezależny od poszczególnych aplikacji. Raczej stara się być wystarczająco wszechstronna, aby objąć istniejące i prawdopodobne przyszłe zastosowania. Dostosowanie do potrzeb dowolnej konkretnej aplikacji lub użytkownika jest zapewniane przez oprogramowanie do obsługi zapytań i prezentacji

Na rysunku jest to dolna warstwa danych, która jest pierwsza, z z niego generowane są widoki zorientowane na aplikację. To holistyczne podejście jest często niewykonalne dla organizacji, które rozwinęły obsługę danych w sposób zdecentralizowany. Częściej rozwiązanie będzie zorientowane na aplikację (lub kilka rozwiązań zorientowanych na aplikacje). Rozwiązanie magazynowe opiera się wówczas na integracji wielu baz danych, które obsługują jedną jednostkę funkcjonalną, na przykład marketing. Jak pokazano na rysunku

dane często występują w postaci tabel w relacyjnych bazach danych. Ze względów historycznych są to często różne roczniki i wzornictwo. Hurtownia aplikacji rozwiązuje skromniejszy problem integracji tych danych w coś, co można przeszukiwać w jednorodny sposób, bez przeprojektowywania podstawowego modelu danych. Nomenklatura jest dość nieprecyzyjnie zdefiniowana, ale hurtownie aplikacji są zwykle większymi i bardziej ambitnymi przykładami data martów, które powstają z nowych lub istniejących baz danych i są przeznaczone do obsługi stosunkowo zwartych procesów biznesowych, takich jak zarządzanie klientami. Bardzo realne niebezpieczeństwo pojawia się, gdy składnice danych nakładają się na dane, które zawierają. Utrzymanie i integralność stają się poważnym problemem i wiele czasu może zająć rozwiązywanie sporów między działami finansowymi i marketingowymi, na przykład, jeśli każdy ma dostęp do innego zestawu danych dotyczących sprzedaży i algorytmów obliczania marży. Niemniej jednak wiele organizacji wybiera tę drogę ze względu na trudności i opóźnienia związane z uzyskaniem zgody kierownictwa na rozwiązanie globalne [64]. Chociaż celem projektowania hurtowni może być stworzenie ogólnego rozwiązania, które jest niezależne od poszczególnych aplikacji, główną cechą takiego systemu musi być to, że jest on zorientowany na biznes, a nie po prostu ogromne repozytorium danych. W szczególności powinien być dostosowany do modelu procesu, a nie tradycyjnego modelu danych [65]. Jednym z powodów, dla których jest to ważne, jest wydajność. Zapytania dotyczące tradycyjnej, jednoprzedmiotowej bazy danych, używanej do obsługi pojedynczej operacji, mogą stosunkowo łatwo przeniknąć dane w sposób optymalizujący wydajność – modelarz danych wie, które są dominującymi jednostkami i atrybutami, i może odpowiednio zaprojektować bazę danych. Jednak tam, gdzie hurtownia ma obsługiwać kilku „masterów”, ich zapytania trafią do bazy z kierunków, których niekoniecznie można było przewidzieć. W związku z tym zwyczaj i praktyka bazy danych mogą wymagać modyfikacji. Na przykład normalizacja, zasada projektowa, zgodnie z którą wpisy nie powinny pojawiać się częściej niż to konieczne, często musi być zaniechana w interesie szybkości [66]. Ponadto, chociaż warto zachować centralną, ogólną koncepcję magazynu, może być konieczne tworzenie podzbiorów danych na lokalnych serwerach, dostosowanych do potrzeb konkretnych jednostek biznesowych. Oprogramowanie magazynowe będzie w tym przypadku zawierało mechanizmy synchronizacji tych lokalnych baz danych z systemem nadrzędnym, z regularną aktualizacją i oznaczaniem danych ze szczegółami ostatniej aktualizacji.