Tam, gdzie osoby lub organizacje chcą się ze sobą komunikować, muszą dzielić wspólny język i zestawy protokołów, aby uniknąć zamieszania i błędów. Od kilkudziesięciu lat uświadamiano sobie, że pojawienie się komputerów i telekomunikacyjnych łączy danych otworzyło drogę do automatyzacji transakcji biznesowych jako sposobu na ich przyspieszenie i zmniejszenie ich błędów, ale tylko wtedy, gdy ten język i protokół istnieją. Metody, które to osiągają, są określane zbiorczo jako elektroniczna wymiana danych lub EDI. EDI to tak naprawdę kompletny proces biznesowy, a nie tylko technologia. Przez lata szereg standardowych podejść w zakresie uzgodnionej definicji procesu, formatów danych i sieci komunikacyjnych zostało rozwiniętych do stanu, który był stosunkowo dojrzały na długo przed tym, jak Internet i sieć stały się wszechobecne. EDI odniosło sukces, ale nie przytłaczająco: jedno ze źródeł twierdzi, że zaledwie 10 000 firm w USA korzysta obecnie z EDI [62]. Problemem był jeden z protokołów własnościowych i konieczność tworzenia umów wymiany międzyzakładowej. Nowoczesne postępy mogą zmniejszyć niektóre trudności, choć nie wszystkie. Dzisiejsze wyzwanie polega na przekształceniu lekcji wyniesionych z „staromodnego” EDI na ich odpowiedniki w środowisku internetowym. Ile zachować, a ile wyrzucić, to wielkie pytanie. Załóżmy, że organizacja A chce używać EDI do prowadzenia interesów z organizacją B. Na przykład, A może chcieć zamówić towary od B w ramach umowy call-off. Jak pokazano na Rysunku , aby to osiągnąć, wymagane są liczne rozważania i działania na różnych poziomach.
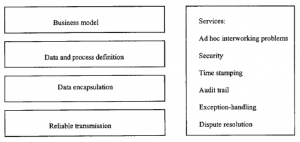
Niektóre części są oczywiste. Na najbardziej podstawowym poziomie musimy stworzyć niezawodną metodę przesyłania danych z jednego komputera na drugi. W przeszłości często osiągano to poprzez łączenie się z siecią prywatną oferowaną przez zewnętrznego dostawcę usług o wartości dodanej (VAS), zwykle firmę telekomunikacyjną lub sieciową (np. AT&Tor IBM). Obecnie i coraz częściej w przyszłości te prywatne sieci zostaną zastąpione publicznymi usługami internetowymi opartymi na protokole TCP/IP i protokołach aplikacyjnych. Szybko zanika potrzeba omawiania standardów transmisji, czy to bezpośrednio między zaangażowanymi firmami, czy za pośrednictwem dostawcy VAS. Musimy również hermetyzować („opakować”) nasze dane z dodatkowymi informacjami, aby umożliwić jednej bazie danych prawidłowe działanie na danych z innej. Na najprostszym poziomie jest to problem z formatowaniem. Na przykład niektóre bazy danych mogą używać znaków ASCII, niektóre binarne. Duża część lukratywnego biznesu dostawców VAS w przeszłości polegała na prostej konwersji kodu ze starych schematów kodowania na bardziej nowoczesne. Ale co z danymi? Co to dokładnie oznacza? Firma X wie, jakie potrzeby chce pominąć; tak samo firma Y i oboje dokładnie wiedzą, co z nią zrobić i jak dopasować ją do swoich procesów biznesowych. Oboje są przekonani, że ich model danych i procesów jest jedynym właściwym dla wykonywanego zadania. Problem polega na tym, że w większości przypadków ich definicje danych różnią się, podobnie jak ich procesy, ponieważ zostały zaprojektowane w izolacji, aby spełnić ich własne postrzegane wymagania. Spójrz na rysunek 2.2, który pokazuje prosty przykład zestawów produktów dwóch firm, X i Y.
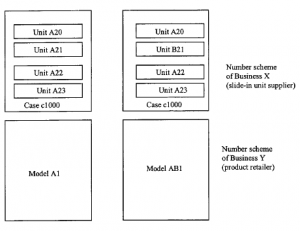
Firma Y sprzedaje produkty na rynku konsumenckim. Produkty te zbudowane są z podzespołów montowanych w skrzyni. Pokazano dwa przykłady: Model A1 to jednostka podstawowa, która składa się z obudowy mieszczącej cztery „standardowe” wsuwane podzespoły. Model AB1 to produkt luksusowy, z jednym z wsuwanych podzespołów (B21) zbudowanym według „lepszego” standardu. Pierwotnie firma Y budowała wszystkie podzespoły obu tych produktów we własnym zakresie. W konsekwencji, finansowa baza danych Y rozróżnia jednostki tylko jako kompletne zespoły, czyli jako „produkty” do sprzedania. Jednak pewnego dnia Y decyduje się na zakup podzespołów. Baza danych jednej firmy produkującej podzespoły, X, dość naturalnie rozróżnia jej pozycje na poziomie podzespołów, jak pokazano. X może opisać dwa różne modele Y całkowicie w kategoriach własnych podzespołów, z wyjątkiem przypadku c1000, który je obejmuje i który może być kupiony od innego dostawcy lub wykonany we własnym zakresie przez Y. Dodatkowo Y może nadal chcieć zachować możliwość wykonania niektórych podzespołów we własnym zakresie lub mieć możliwość zakupu podzespołów od innych dostawców. Oczywiście, chociaż Y sprzedaje rzeczy na poziomie produktu, a nie na poziomie podzespołów, Y musi teraz stworzyć jakiś sposób oddzielnej identyfikacji podzespołów w ramach swojego procesu produkcyjnego (zazwyczaj poprzez organizację rysunków montażowych w swoim biurze kreślarskim), ale niekoniecznie w jego finansowej bazie danych. Y ma spory problem: produkty nie mapują jeden do jednego na podzespoły, przynajmniej na kody stosowane przez dostawców podzespołów. Są dalsze komplikacje: X użyje wielu różnych komponentów do budowy swoich podzespołów, niektóre z nich może z kolei kupić od swoich dostawców. X musi identyfikować te komponenty jako odrębne elementy pod względem zakupów, ale jeśli funkcjonalność jest taka sama, nie musi rozróżniać ukończonych podzespołów na podstawie marki komponentów, które zawierają. Ale „funkcjonalność” jest trudna do zdefiniowania: X mógł dostarczać podzespoły do firmy Z, która umieszcza je w pojemnych skrzyniach, gdzie niewielka różnica wymiarowa podzespołów spowodowana przez różne komponenty nie stanowi problemu, ale przypadki Y mogą być mniejsze. Tak więc istnieją przypadki, w których Y wymaga, aby X przyjął drobniejszą szczegółowość specyfikacji, niż X kiedykolwiek uważał za konieczny do jej wewnętrznego użytku. Zagmatwane? Taki właśnie ma być ten przykład, ponieważ przedstawia on naprawdę mylące problemy z nomenklaturą danych, które pojawiają się każdego dnia, gdy firmy decydują się na zintegrowanie swoich transakcji. Określenie, jakie dane należy przekazać, co te dane „oznaczają” i co z nimi zrobić, jest bardziej złożone niż na pierwszy rzut oka. Jak pokazuje rysunek 2.2, musimy kierować całość z punktu widzenia biznesowego – zrozumienie, czym naprawdę „jest” produkt – a następnie opisać dane i procesy, które definiują i manipulują ciągiem informacji używanym do opisania produktu i wszystkie operacje komputerowe z tym związane. Zwróć uwagę, że w omawianym przykładzie rozważaliśmy sytuację obracającą się wokół „produktu”. Istnieją inne możliwe punkty widzenia (na przykład punkt widzenia procesu dla odprawy celnej towarów), ale podstawowe zasady pozostają takie same: najpierw zdefiniuj punkt widzenia biznesowego, a następnie struktury danych i procedury, a następnie cięcie kodu. Podany przez nas przykład mógł być mylący, ale i tak było to uproszczenie. To znacznie prostsze niż w prawdziwym życiu. Aby zilustrować tę kwestię, przyjrzyjmy się teraz dalszemu przykładowi. Nadal patrzymy na rzeczy z punktu widzenia produktu. Co może być bardziej odpowiedniego przy wyborze przykładu produktu niż „książka”?