Sama czynność projektowania hurtowni danych może być korzystna sama w sobie: znacznie wyraźniej przybliża prawdziwą naturę kluczowych procesów biznesowych organizacji. Ale magazynowanie ma na celu coś więcej. Mając w pełni zapełniony i w miarę dokładny magazyn, firmy miałyby nadzieję, że będą w stanie wydobyć informacje, które pomogłyby im w lepszym prowadzeniu i/lub przeprojektowywaniu procesów biznesowych. Istnieje co najmniej jedna podstawowa różnica między bazą danych zbudowaną w celu napędzania procesu biznesowego, taką jak obsługa zamówień, a bazą danych wspierającą podejmowanie decyzji, z której wyodrębniane są informacje przeznaczone do prowadzenia strategii, na przykład ocena wyników sprzedaży regionalnej i planowanie kampanii marketingowej: operacyjne bazy danych to zazwyczaj odczyt lub zapis jednej pozycji danych na raz, np. złożenie zamówienia na konkretny produkt, dla konkretnego klienta. Jest to jeden z powodów, dla których standardową praktyką przemysłową stało się korzystanie z relacyjnych baz danych, których indywidualne rekordy można w ten sposób uzyskać dostęp i aktualizować. Z drugiej strony bazy danych do wspomagania decyzji zasadniczo agregują i uśredniają informacje w próbce rekordów danych. („Podaj średnią sprzedaż na klienta w Regionie Północnym, Regionie Południowym, Regionie Wschodnim” itp.) Ze względu na dobre praktyki utrzymywania danych, takie jak normalizacja, wyszukiwanie tych informacji może obejmować odczytywanie wielu różnych tabel. Nawet jeśli tak nie jest, dostęp do każdego pojedynczego rekordu, który spełnia kryteria, może być bardzo powolnym procesem w przypadku dużych baz danych. Za pomocą tej metody może nie być możliwe zapewnienie przetwarzania analitycznego on-line (OLAP), nazwy nadanej usługom wspomagania decyzji, które są dostępne, a ich dostarczenie nie zajmuje godzin lub dni. Rozwiązanie tego problemu jest w zasadzie proste i można je budować na istniejących bazach danych. Wystarczy z góry zdecydować, jakimi kategoriami (lub „wymiarami”) danych chcesz zarządzać — sprzedażą, regionami, grupami demograficznymi klientów itp. — a następnie okresowo wstępnie obliczyć agregaty dla każdego z tych wymiarów. aktualizacja w miarę pojawiania się nowych transakcji. Użyliśmy terminu wymiar dla każdego z elementów zarządzania. Jest to zwykłe określenie, które dało początek innej koncepcji szeroko stosowanej w OLAP – Datacube. Załóżmy dla uproszczenia, że rozważamy tylko trzy wymiary: produkt, region, marża zysku. Następnie możemy przedstawić nasze agregaty danych jako umieszczone w „kostce”
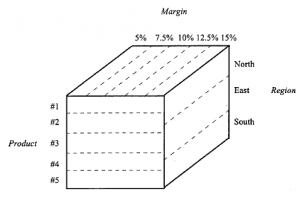
Osie sześcianu to kolumny lub pola w modelu danych operacyjnych, a wartość, marża zysku ze sprzedaży produktu 3 w Regionie Wschodnim, znajduje się w odpowiednim zestawie trzech współrzędnych (trójka) w tym obszarze. Nie ma matematycznego powodu, dla którego musimy trzymać się trzech wymiarów. Wszystkie reguły przetwarzania danych będą działać dla „hiperkostek” o dowolnie wielu wymiarach, ale znacznie ułatwia to wizualizację przez człowieka i wydajność przetwarzania, jeśli ograniczymy liczbę wymiarów do małej wartości. Oczywiście możemy obliczyć kostki, których osie są różne: wiek klienta, grupa społeczno-ekonomiczna, kod pocztowy, kwartały w ciągu roku itd., a dane zarządzania zwykle definiuje się jako serię tych kostek, które zasilają wielowymiarowy system wspomagania decyzji
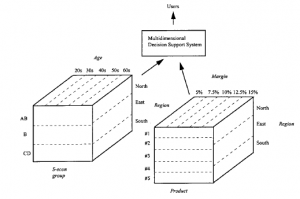
Istnieją pewne ograniczenia liczby kostek i całkowitej liczby wymiarów, które może obsłużyć OLAP, zarówno pod względem czasu przetwarzania, jak i przechowywania. Aby jak najlepiej wykorzystać te systemy, należy najpierw zastanowić się nad wyborem wymiarów, które w najbardziej zwięzły sposób reprezentują kluczowe zmienne organizacji. Dostawcy magazynów i DSS czasami argumentują, że najlepiej jest wybierać je w dużej mierze na podstawie danych zorientowanych na klienta, ponieważ najprawdopodobniej ujawnią one trendy, które można wykorzystać do zwiększenia rentowności. Problemem jest również architektura bazy danych OLAP. Chociaż koncepcja jest kostką logiczną, baza danych, która jest jego podstawą, może być zaprojektowana na wiele sposobów. Najbardziej radykalne jest odwzorowywanie logicznego sześcianu przez kostkę pamięci, a właściwie zbiór tablic, które razem tworzą zredukowaną wersję kostki, z pominięciem pustych punktów danych. Inne podejścia modyfikują lub rozszerzają tradycyjną bazę danych relacji. Aby uzyskać więcej informacji na ten temat, a także argument, że rzadkie macierze prawdopodobnie zostaną przyjęte w przypadku małych/średnich rozwiązań