Zawsze były problemy z integralnością danych, ale w eBiznesie będzie to jeszcze większy problem, z co najmniej trzech powodów: po pierwsze, wzrośnie sama ilość danych, a więc proporcjonalnie wzrośnie potencjał błędu. Po drugie, łączenie istniejących organizacji w tymczasowe, rozszerzone przedsiębiorstwa doprowadzi do niezgodności między systemami i być może niechęci do przyjęcia odpowiedzialności za naprawienie rzeczy, zwłaszcza za wspieranie tego, co jest postrzegane jako przejściowe relacje. Po trzecie, utrata kontroli nad wprowadzaniem danych. Zamiast stosunkowo niewielu, dobrze wyszkolonych i nadzorowanych pracowników wprowadzania danych, środowisko internetowe przewiduje, że znaczny procent danych wprowadzanych jest przez klientów i dostawców, którzy mają niewielką wiedzę lub chęć dbania o system, który nie jest ich własnym. Będzie też rosnąca ilość danych pochodzących ze stosunkowo niedokładnych kodów kreskowych i innych czytników. Ogólnie rzecz biorąc, dane będą pochodzić ze źródeł o znacznie mniejszej liczbie wbudowanych funkcji sprawdzania jakości. Problemem do rozwiązania jest to, jak poprawić te dane po ich zebraniu, a przynajmniej jak zminimalizować ewentualne szkody. Wcześniej w tym rozdziale opisaliśmy trzy koncepcyjne etapy tworzenia baz danych i hurtowni e-biznesu. Integralność danych można poprawić, przetwarzając je w trzech głównych punktach cyklu.
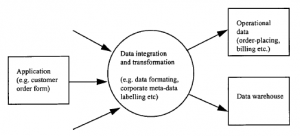
Pierwszym miejscem, w którym możemy zweryfikować dane i wykluczyć błędy, jest konkretna aplikacja, np. formularz zamówienia. Oczywiście bardzo ważne jest zapewnienie przeprowadzenia jak największej liczby kontroli przed zaakceptowaniem danych. Należy egzekwować i być może ponownie egzekwować standardowe praktyki tworzenia sum kontrolnych danych. (Sumy kontrolne są wczesną formą podpisu cyfrowego, zwykle stosowaną do produktu lub mechanizmu płatności: wyobraź sobie przypadek, w którym produktom firmy są przypisywane kody numeryczne w prostej kolejności całkowitej. Na tym kodzie wykonywana jest operacja matematyczna, która powoduje wygenerowanie dodatkowe cyfry, które są dołączane do oryginalnego kodu w celu utworzenia pełnego kodu dla produktu. Operacja cyfry kontrolnej jest wykonywana przez dowolny system, który otrzymuje kod produktu. To odwraca działanie matematyczne i sprawdza, czy cyfry kontrolne i podstawowe kod są kompatybilne na przykład bardzo prostym podejściem może być dodanie „1” do wszystkich nieparzystych kodów produktów i „0” do wszystkich parzystych. W obu przypadkach zsumowanie cyfr dałoby liczbę parzystą, chyba że dane zostały po drodze uszkodzone. Jest to bardzo szczątkowe i niezbyt dokładne lub wydajne rozwiązanie, ale demonstruje zasadę.) O ile to możliwe, granice wartości danych należy sprawdzić przy najbliższej okazji. Formularze internetowe można sprawdzić na kliencie, zanim zostaną wysłane na serwer, za pomocą apletu Java przesłanego z formularzem. Dzięki temu można upewnić się, że pole kodu pocztowego zostało wypełnione, sprawdzić datę urodzenia, aby sprawdzić, czy mieści się ona w dopuszczalnych granicach i tak dalej. Jednak nie zawsze jest możliwe przeprowadzenie tych kontroli w tym momencie. Klienci mogą nie być w stanie zaakceptować apletów lub nie chcą ich akceptować. Aplikacja może być zbyt stara, aby można ją było skutecznie przepisać z uwzględnieniem kontroli integralności. Może się zdarzyć, że z wielu innych powodów nie jest możliwe przeprowadzenie wszystkich kontroli na etapie wejściowym. W każdym razie przejdą niektóre błędy. Istnieje również problem z semantyką danych lokalnych i korporacyjnych. Znaczenie terminu dotyczącego danych w jednym wniosku może nie odpowiadać dokładnie znaczeniu terminu o podobnej nazwie w innym: typowym przykładem może być termin „lokalizacja”. Dla jednej aplikacji lub jednej firmy w przedsiębiorstwie może to oznaczać dzielnicę kodów pocztowych, inną konkretną zatokę magazynową. Istnieje potrzeba pogodzenia tych różnych punktów widzenia, które nie są błędami, ale nadal mogą zepsuć procesy biznesowe. Temu problemowi uzgadniania zwykle nadaje się znacznie bardziej pozytywną nazwę: integracja i transformacja danych. Tutaj potrzebujemy mieszanki oprogramowania, które w pierwszej kolejności potrafi odwzorować niskopoziomową strukturę danych – m.in. relacyjne i płaskie bazy danych – do wspólnego formatu do przetwarzania, a następnie przeanalizuj je, aby sprawdzić, czy nie zawiera anomalii. Bardzo prostym przykładem może być odkrycie, że firma, która najwyraźniej zawsze znajduje się pod jednym adresem w jednej aplikacji, zawsze znajdowała się pod innym w innej aplikacji. Jeszcze bardziej podstawowe kwestie, takie jak bazy danych, które obcinają dane wejściowe przy różnych długościach, muszą zostać podjęte. Oczywiście tego typu problemy nie mogły zostać wykryte na etapie pojedynczej aplikacji. Etap integracji i transformacji dodaje zatem wartość do poszczególnych strumieni danych aplikacji, porównując je z korporacyjnymi modelami danych używanymi przez hurtownię danych i operacyjne bazy danych, oznaczając niespójności, a następnie dodając deskryptory metadanych, zanim dane zostaną dopuszczone do wejść do magazynu lub kierować procesem operacyjnym.