Jak donosi WWW.org, nie ma w pełni ustandaryzowanego podejścia do mikropłatności za towary lub usługi dostarczane w sieci. Niedawno wydali publiczny projekt [104], który próbuje określić wytyczne dla takiego podejścia. Celem jest przedstawienie opisu procesu obsługi łącza za opłatą, który ułatwi programistom oznaczanie stron internetowych w standardowy sposób i zapewni użytkownikom tych stron prosty mechanizm „kliknij, aby zapłacić”. Zasadę przedstawiono na rysunku.
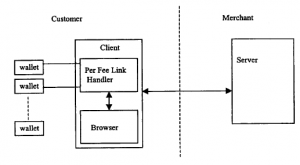
Moduł obsługi łącza Per Fee znajduje się na komputerze klienckim użytkownika. Służy do komunikacji z serwerem sprzedawcy za pomocą protokołu HTTP. (Ściśle zalecany jest bezpieczny wariant SSL/HTTPS, omówimy to dalej w następnej sekcji.) Komunikaty, które przechodzą między klientem a serwerem, muszą być kompatybilne z istniejącymi przeglądarkami. W tych komunikatach określona jest liczba pól obowiązkowych, zalecanych i opcjonalnych. Obejmują one:
† Lokalizacja on-line strony sprzedawcy (obowiązkowe).
† Nazwa sprzedawcy (opcjonalnie).
† Odniesienie on-line do tego, co jest kupowane (obowiązkowe).
† (krótki) tekstowy opis tego, co jest kupowane (obowiązkowe).
† (długi) opis (zalecane).
† Obraz/opis graficzny (opcjonalnie).
† Cena (obowiązkowe).
† Trwałość w czasie witryny sprzedaży (zalecane).
(Istnieją inne, mniej oczywiste terminy. Więcej szczegółów można znaleźć na stronie.) Działania W3C zalecają sposoby osadzenia tych informacji w istniejących przeglądarkach HTML, przy użyciu prostego mechanizmu „wtyczek” lub jako apletu JAVA. (Zauważ, że ten drugi kurs nie jest zalecany dla HTML w wersji 4.0 i nowszych, gdzie preferowanym rozwiązaniem jest element OBJECT. Ponownie, zobacz pełny tekst, aby uzyskać szczegółowe informacje.) Omówiono również pojawiające się zastosowania XML. Grupa zarekomendowała również projekty, które jasno pokazują użytkownikom, że podążają za linkiem płatnym, na przykład wyświetlając tytuł linku w formularzu „Chcę to kupić”.