Chociaż w najlepszym z możliwych światów projektowanie systemów informatycznych dla przedsiębiorstw powinno zaczynać się od odgórnego określenia, czym chcemy zarządzać, a następnie integracji śrub i nakrętek, które to zapewnią, prawie nigdy nie zaczynamy od tak korzystnego punkt widzenia: dziedzictwo i liczne inicjatywy w ramach zainteresowanych organizacji zwykle to uniemożliwiają. W związku z tym należy wykonać dość dużo pracy, po prostu łącząc to, co już istnieje. Zazwyczaj zasoby danych organizacji znajdują się w wielu miejscach, w różnych formatach
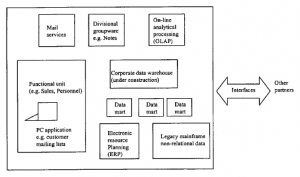
Pozycja pokazana na rysunku przedstawia realia wielu organizacji. Często stanowią one pole bitwy między zintegrowaną, ale być może nie reagującą lub biurokratyczną kontrolą sprawowaną przez dział IS firmy, a nowszymi, fragmentarycznymi inicjatywami podejmowanymi przez poszczególne jednostki funkcjonalne, które szybciej tworzyły własne data marty. W tę i tak już zagmatwaną scenę został wrzucony korporacyjny Intranet, który ma zapewnić każdemu w organizacji bezpośredni dostęp online do wiedzy korporacyjnej. W takich sytuacjach oczekiwania tych osób są czasami bardzo zawiedzione, gdy powiedziano im, że jedynym sposobem, w jaki można uzyskać dostęp do plików z jednego systemu przez inny, jest fizyczny transport taśm lub dysków z danymi. To nie wszystko, często dane muszą być następnie uruchamiane przez programy konwertujące w trybie off-line, których opracowanie zajmuje trochę czasu i może zapewnić tylko bardzo ograniczone okna na dane, ze względu na różnice w modelach danych. Nawet jeśli fizyczny transport można zastąpić często drogi i wciąż raczej powolny, masowy transfer plików drogą elektroniczną (rysunek 2.9), przy użyciu takich metod, jak Internet File Transfer Protocol (FTP), integracja aplikacji nie jest łatwa do uzyskania na różnych platformach. Ponadto dane nie są statyczne.
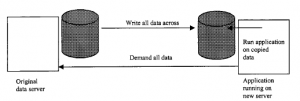
Zmienia się, a zmiany te muszą być zsynchronizowane we wszystkich aplikacjach składających się na proces biznesowy. Transfer plików między procesami nie musiałby zatem odbywać się tylko raz, ale za każdym razem, gdy odpowiednie dane uległyby zmianie. To szybko staje się niemożliwe do opanowania. Zamiast tego dane powinny być utrzymywane tylko na platformie hosta i tylko odpowiednie ich części są pobierane przez zależne procesy znajdujące się w innych systemach, gdy jest to wymagane. Aby to osiągnąć, jednym podejściem jest zastosowanie zasad komponentów, jak opisano we wcześniejszej dyskusji o architekturze

Komponenty, które są interfejsem między dwoma systemami, muszą być zdolne do utrzymania niezawodnej komunikacji poprzez interfejs, być może z pełną integralnością przetwarzania transakcji, zaangażowaniem i wycofaniem. W praktyce zarządzanie tym może odbywać się za pomocą oddzielnego pakietu oprogramowania uruchomionego na osobnym serwerze. Podstawowym wymogiem jest to, że struktura danych jednej bazy danych musi być odwzorowana na strukturę drugiej: typowym przykładem tego jest konwersja wartości jednostkowych – wagi funtów na kilogramy, dolarów amerykańskich na franki francuskie itp. – które mogą wystąpić w przypadku budowania przedsiębiorstw wielonarodowych. Innym powszechnym przykładem są tabele danych relacyjnych baz danych: niektóre mogą używać jednej kolumny zawierającej adres i kod pocztowy, podczas gdy inne, które przyjęły marketing kodu pocztowego, mogą podzielić adres i kod na dwie oddzielne kolumny. Oczywiście zaletą jest tworzenie rozwiązania (komponentowego lub innego), które dostarcza programistom zestaw narzędzi, które w prosty sposób pozwalają na konstruowanie reguł przeprowadzania takich konwersji. Obecnie istnieje szereg rozwiązań komercyjnych. Zobacz na przykład Hummingbird’s Genio Suite. Oczywiście pojawiają się problemy z wydajnością, gdy uruchamiamy aplikacje, które mogą wymagać nie tylko złożonych zapytań o dane, ale nawet bardziej złożonych i czasochłonnych procesów pośredniczących, które mogą być uruchamiane na danych. Jednym z rozwiązań jest zapewnienie hierarchicznego zestawu procesów, z prostymi wywoływanymi do prostych zadań i delegowanie jak największej ilości pracy do istniejących silników baz danych, które są zoptymalizowane pod kątem własnych danych. W przypadku bardziej złożonej wymiany danych wymiana może być prowadzona przez program zarządzający, działający na osobnym serwerze. Ponadto, gdy bazy danych znajdują się na tym samym serwerze lub są bezpośrednio połączone przez bramę komunikacyjną, czasami możliwe jest umożliwienie im bezpośredniej komunikacji, zmniejszając w ten sposób potrzebę „puzonowania” strumienia danych od źródła do serwera zarządzającego do miejsca docelowego.