Przeniesienie interfejsu z klientami z call-center do centrum obsługi poczty e-mail może obniżyć koszty, ale jedynie przenosi ból związany z zarządzaniem z jednej operacji na drugą. Wciąż musi być jakiś sposób na oddzielenie zapytań o informacje od skarg klientów; wciąż musi być sposób, aby na podstawie tych danych zauważyć, że występują problemy z konkretnymi produktami i powiadomić o tym projektantów. Istnieje wiele innych obszarów, w których zwiększona ilość informacji, zarówno w organizacji, jak i w jej obrębie, musi zostać przeanalizowana i zrozumiana, najlepiej przez maszynę. Specjalistyczne firmy w dziedzinie oprogramowania do zarządzania wiedzą zaczynają oferować rozwiązania, które „inteligentnie” analizują dane korporacyjne i kierują je na właściwy obszar do rozwiązania. Mówi się, że możemy decydować o tym, czy informacja jest ważna, jeśli najpierw wiemy, czego ona dotyczy. Pojęcie „około” może wydawać się bardzo abstrakcyjne i trudne do zdefiniowania w formalny sposób, ale coraz częściej firmy konstruują narzędzia do ekstrakcji wiedzy, które mogą tworzyć operacyjnie zadowalające wyjaśnienia dotyczące „około”. Dość dokładnym sposobem myślenia o organizowaniu wiedzy jest rozważenie, że jest ona poddawana wielu zapytaniom, które można sformułować w terminach języka naturalnego, takich jak „Kto jest zaangażowany?”, „O czym to jest?”, „Dlaczego zostało to zrobione?” wyprodukował?”, „Kiedy coś się wydarzyło?”, „Gdzie?”, „Jak (w ramach którego procesu) powstało”, „Ile (lub jakie są liczby)?” Nie jest to szczególnie trudne wymienić kilka sposobów, w jakie można opisać znaczenie elementu danych elektronicznych:
† Według tytułu.
† Przez fragment metainformacji, której definicja została opublikowana.
† Przez kto to napisał.
† Do kiedy zostało napisane.
† Według jego zawartości.
† Poprzez linki do iz niego przez inne elementy.
† Po wyglądzie (kolorowa broszura, arkusz kalkulacyjny itp.).
i są inne. Można zauważyć, że dokumenty nie istnieją tylko w izolacji, ale istnieją w wielu kontekstach, które obejmują ludzi, którzy z nimi pracują i procesy biznesowe, które wspierają i zmieniają się z czasem, a nie są skamieniałościami, które się nie zmieniają. Rysunek wyjaśnia to dokładniej
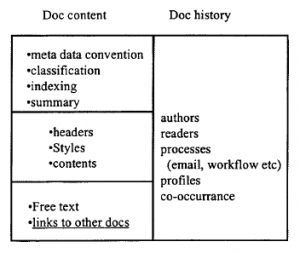
Na rysunku dokument jest reprezentowany na dwa sposoby. Po pierwsze, przez jego „treść”, która składa się z rdzenia, tematu i wszelkich dodatkowych metainformacji dodanych do niego przez ludzkich lub maszynowych interpretatorów. Po drugie, poprzez swoją historię – w jaki proces był zaangażowany, kto ją przeczytał, umieścił ją w swoim osobistym profilu jako typowy przykład rzeczy, o których chciała usłyszeć i tak dalej. Jest oczywiste, że niektóre z tych informacji są jawnie, nawet świadomie, stosowane w danych: większość raportów w dzisiejszych czasach jest pisana przy użyciu standardowych „stylów” dla różnych poziomów nagłówków itp. większość ma arkusze treści; arkusze kalkulacyjne i bazy danych mają nagłówki kolumn, które w pewien sposób odnoszą się do korporacyjnych modeli danych i słowników; czasami autorzy lub tłumacze stosują słowa kluczowe do dokumentu, w HTML lub XML ,meta. definicja; czasami silniki baz danych automatycznie indeksują dowolny tekst dokumentu, wyodrębniając słowa i ich częstotliwość, które mają działać jako przeszukiwalne maszynowo podsumowanie dokumentu. Jednak wiele informacji o użyciu dokumentu jest tworzonych w ukryciu (choć nie w zamierzonym sensie). Jeśli to ma być użyte jako część dowodu na temat około, to również musi być wpisane do metaopisu i aktualizowane tak często, jak to konieczne. Zatem podstawowym zadaniem rozwiązań do zarządzania wiedzą jest integracja szeregu zbiorów danych generowanych przez procesy poprzez oznaczanie ich etykietami indeksowymi i informacjami źródłowymi, a następnie obserwowanie późniejszej historii danych i ciągłe aktualizowanie tego rekordu wraz z wykorzystaniem silniki wnioskowania, wyposażone w szczątkową inteligencję, które próbują osiągnąć prostą parę celów:
1 Dostarcz wszystkim właściwym osobom wszystkie dane ważne i istotne dla ich obszaru pracy (wymóg wycofania).
2 Bez dostarczania niczego, co nie jest konieczne (precyzja wymogu).
Ogólnie rzecz biorąc, istnieje wzajemna zależność między precyzją a wydajnością procesu wyszukiwania informacji
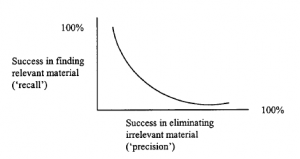
Zauważ, że może to utrudnić porównywanie systemów wyszukiwania wiedzy. Niektórzy mogą błędnie dawać za dużo, inni wolą dawać mniej, z szansą na utratę czegoś ważnego. Ponownie wybór nie jest absolutny; będzie to zależeć od aktualnych wymagań obecnej populacji użytkowników, biorąc pod uwagę dzisiejszy zestaw danych.