Punktem wyjścia dla większości praktycznych systemów jest próba wyodrębnienia tematu ze źródeł danych. Proces ekstrakcji z konieczności polega na wzięciu dłuższego tekstu i skróceniu go do krótszego. Odbywa się to częściowo w celu poprawy wydajności przetwarzania na kolejnych etapach, ale także dlatego, że ekstrakcja w pewnym sensie dociera do „istoty” dokumentu. Jedna z najprostszych metod polega na sporządzeniu listy poszczególnych słów użytych w tekście. Użytkownicy, którzy proszą o informacje dotyczące tego słowa, mogą otrzymać wszystkie dokumenty, które zawierają to słowo na swoich listach. Proces można ulepszyć, jeśli chodzi o przywoływanie, poprzez sedno: chociaż użytkownicy proszą o informacje na temat „psa”, proces ma bazę danych, która rozszerza termin na „psy”, „psy dwuosobowe”, „pies myśliwski” itp. Prosty doprecyzowanie może polegać na indeksowaniu dokumentów, aby dowiedzieć się, ile razy każde słowo występuje jako ułamek całkowitej długości tekstu. Zwykle wyklucza się wszystkie bardzo popularne słowa, takie jak „the”, „and”, „is” itp., umieszczając je na liście stop, która jest używana przez program indeksujący. Tak więc, biorąc pod uwagę prośbę użytkownika o teksty z „gazem” (powiedzmy), teksty mogą być wymienione w kolejności malejącej częstotliwości, co sprzyja precyzji. Można jednak zrobić więcej, stosując tę prostą strategię uwzględniania liczby słów: możliwe jest opisanie tekstu w kategoriach porównania całej listy z listami wygenerowanymi dla innych dokumentów (rysunek 2.18). Dokument po lewej stronie rysunku to taki, który zainteresował użytkownika. Pokazana jest część jego indeksu słów, w szczególności słowa „lpg”, „oktan”, „gaz”, „auto” wraz z miarą ich częstotliwości występowania. Po prawej stronie znajdują się statystyki dla tych słów uśrednione w całej bazie danych.
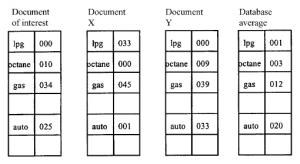
Teraz, nawet nie wiedząc, że nastąpiło indeksowanie, użytkownik mógł powiedzieć: „Znajdź więcej dokumentów na ten sam temat”. Wyszukiwarka przeszukuje bazę danych, porównując indeks interesującego dokumentu ze wszystkimi innymi. Rozważmy dwa przypadki takiego porównania, z dokumentami X i Y. Bez uciekania się do skomplikowanej matematyki, możemy zobaczyć, że dokument Y jest „znacznie bardziej podobny” do dokumentu będącego przedmiotem zainteresowania niż średnia lub dokument X. W szczególności zauważamy częste występowanie ‘gas’ ORAZ ‘auto’ zarówno w Y, jak iw interesującym dokumencie. Prawdopodobnie oznacza to, że łączy ich wspólne zainteresowanie „gazem” w kontekście jego amerykańskiego wykorzystania jako „benzyny”. Używając łącznych prawdopodobieństw słów, możemy zacząć definiować dla nich podstawowe „znaczenia” indywidualnie: „gaz” = „benzyna” kontra „gaz” = „gaz ziemny”, ponieważ ten pierwszy ma tendencję do kojarzenia się z takimi rzeczami, jak „samochody”. (= ‘samochody’) zamiast ‘lpg’ = ‘gaz ziemny’. Gdybyśmy przyjrzeli się dokładniej, jak zrobiliśmy to intuicyjnie, odkrylibyśmy, że zasadniczo mierzyliśmy dla każdego dokumentu, jak zmienia się stosunek (częstotliwość w dokumencie)/(średnia częstotliwość we wszystkich dokumentach) dla każdego terminu. Stosunek znacznie większy lub mniejszy niż jeden dla tego terminu oznacza, że jest wysoce nietypowy. Dokumenty, które mają wiele nietypowych cech, prawdopodobnie dotyczą tego samego tematu. Stosunek częstotliwości terminów w dokumencie do średniej częstotliwości jest znany jako miara TF-IDF (Term Frequency Inverse Document Frequency) i jest powszechnie używany do lokalizowania „podobnych” dokumentów. W tym przykładzie dla uproszczenia założyliśmy, że użytkownik prosi wprost o podobne dokumenty i robi to jako pojedyncze zapytanie. W rzeczywistości silniki zarządzania wiedzą zwykle eliminują potrzebę zgłaszania tego żądania przez użytkowników. Wiele z nich jest zaprojektowanych do działania w proaktywnym trybie push: stopniowo tworzą listy preferowanych słów w ramach pozyskiwania profili użytkowników. Listy te są modyfikowane przez sposób użytkowania i okresowe proszenie użytkowników o wyrażenie preferencji. Po uzyskaniu zestawu profili dla każdego użytkownika, system może następnie, bez monitowania, wysyłać użytkownikom wiadomości informujące o nadejściu dokumentów pasujących do profilu.