Pierwotnie obliczenia biznesowe były wykonywane jako zadanie punktowe, bez rzeczywistej koncepcji działania w sieci. Istnieją dwa bardzo proste podejścia architektoniczne do tego: komputer mainframe i głupi terminal lub izolowana osobista stacja robocza. Chociaż te pierwsze mogły być preferowanym sposobem pracy dla dużych firm, a drugie wyborem dla małych firm, pod wieloma względami są one równoważne. Ich wspólną cechą jest to, że wszystkie procesy biznesowe są uruchamiane na jednej platformie lub jednej warstwie
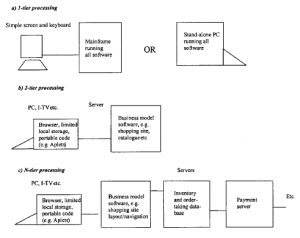
Obecnie wiele systemów ewoluowało w kierunku podejścia klient-serwer (dwuwarstwowego), w którym większość procesów biznesowych działa na serwerze, a klient zajmuje się głównie prezentacją i przechowuje tylko ograniczoną ilość danych specyficznych dla użytkownika. Następnym etapem jest architektura trójwarstwowa, w której większość procesu (w praktyce prosta procedura zakupów w sieci Web) działa na jednym serwerze i pobiera dane z serwera bazy danych, trzeciego poziomu. Potem sprawy stają się bardziej skomplikowane, a dodatkowe aplikacje działają na różnych warstwach. W artykułach na ten temat często nie wyjaśniono, że poziomy są logiczne, a nie fizyczne. Nie ma jednej warstwy na serwer/komputer ani jednego komputera/serwera na warstwę. Na jednej maszynie można uruchomić kilka warstw biznesowych, a warstwy mogą być rozmieszczone na kilku komputerach. Jest to znane i uznawane przez architektów systemów jako powód zamieszania. Jednak terminy te są szeroko stosowane i należy być przynajmniej świadomym ich istnienia.
Powinniśmy również zauważyć, że architektury wielopoziomowe powstały niekoniecznie dlatego, że temu wyborowi architektury poświęcono wiele uwagi; w rzeczywistości są one bardziej wynikiem prób jak najlepszego wykorzystania tego, co tam było. Jednym z powodów, dla których projektowanie e-biznesu jest tak złożone, jest to, że potrzebujemy kilku komputerów do wspólnej pracy w wielu geograficznie odseparowanych lokalizacjach, pomimo w wielu przypadkach innego sprzętu i oprogramowania. Mogą pochodzić od różnych dostawców i mogą mieć ponad dwadzieścia lat. Dzisiaj, gdybyśmy mogli projektować od zera, moglibyśmy preferować projekty sprzętowe oparte na klastrach stosunkowo małych, kompatybilnych komputerów i pisać programy przy użyciu orientacji obiektowej i przenośnego kodu. Jednak wiele systemów biznesowych, które nadal działają, opiera się na scentralizowanych big boxach, aby uruchamiać wszystkie swoje procesy lokalnie i wdrażać relacyjne lub nawet płaskie bazy danych oraz kodowanie COBAL lub zastrzeżone. Mogą przechowywać dane, które trudno zintegrować z warstwowymi modelami danych bardziej nowoczesnych struktur baz danych. W zamian mogą cieszyć się bardzo wysokim poziomem bezpieczeństwa i integralności transakcyjnej. Ewolucja przetwarzania warstwowego w wielu przypadkach będzie po prostu niemożliwa do wyrzucenia starych i wprowadzenia nowych bez narażania firmy na ryzyko. Z tego powodu rozwiązania do budowy rozbudowanego przedsiębiorstwa elektronicznego musiały być pragmatyczne. Nikt poważnie nie zasugerował, że powinien istnieć system operacyjny e-biznesu, który zastąpiłby dotychczasowe. Nie byłoby również możliwe przepisanie całego zastrzeżonego oprogramowania biznesowego. Zamiast tego podejście, jak zobaczymy, opiera się na budowaniu rozproszonego oprogramowania pośredniczącego, które może pośredniczyć między różnymi lub rozproszonymi systemami. W szczególności na tym polu konkurują i współpracują obecnie Microsoft DCOM, otwarta architektura CORBA oraz rozwiązania Enterprise Java. Ze względu na złożoność procesów i różnorodność maszyn, te rozwiązania oprogramowania pośredniego mogą powodować poważne wąskie gardła, jeśli nie zostaną uwzględnione w projekcie.