Coraz częściej dostawcy oferują rozwiązania, w których część rozpoznawania istotnych wzorców jest realizowana przez komputer. Zamiast po prostu odpowiadać na zestawy zapytań generowanych przez użytkowników i opartych na hipotezach użytkownika, bardziej zaawansowane systemy mogą same przeprowadzać eksploracyjną analizę danych, tworząc same hipotezy i grupując dane w znaczące lub przynajmniej przydatne wzorce. Tym wzorom zazwyczaj przypisuje pewien statystyczny poziom dokładności. Na przykład sprzedawca detaliczny może chcieć znaleźć „odpowiednie” wzorce cech klientów w danym obszarze kodu pocztowego. Następnie zażądają od inteligentnego oprogramowania „znalezienia wzorców związanych z obszarem pocztowym X”. System może odpowiedzieć, obliczając statystyczne współzachowanie szeregu parametrów dla tego obszaru i zwracać regułę, która mówi: „w obszarze X istnieje 83% szans, że osoby powyżej 45 roku życia, które wykupiły od Ciebie ubezpieczenie na życie, pytałem również o ubezpieczenie zdrowotne”. Oczywiście parametry „kod pocztowy”, „wiek”, „ubezpieczenie na życie” (lub ich proste pochodne) muszą być jednostkami lub atrybutami w bazowym modelu danych. Istnieje również możliwość, że oprogramowanie może wygenerować zbyt wiele statystycznych „reguł” tego typu, jeśli po prostu zostanie zaprogramowane na tych liniach. Bardziej satysfakcjonujące jest poproszenie go o opracowanie reguł opisujących nietypowe zachowanie, w naszym przykładzie, być może informujących nas o obszarach z kodem pocztowym, w których zapytania w wieku 45 lat i osób były niezwykle wysokie. Zauważ, że reguły wymienione powyżej są zasadniczo sposobami kompresji dużej liczby zbiorów danych w znacznie bardziej zwartą i wydajną metodę przetwarzania, a ponadto taką, która jest łatwiejsza do zrozumienia dla człowieka. Rozumowanie oparte na regułach ma również tę zaletę, że można je wyrazić formalnie, w kategoriach logicznych, co prowadzi do łatwości programowania. Jak wszystkie systemy, które tworzą ogólne widoki konkretnych danych, jest to jednak przybliżenie i z czasem może wymagać udoskonalenia. (Być może trzeba będzie nawet zrezygnować, jeśli zmienią się okoliczności). Zaawansowane systemy OLAP przeprowadzają powtarzające się kontrole tego typu reguł. Niektóre schematy wręcz „eksperymentują” z regułami, modyfikując ich parametry poprzez dodanie małego elementu losowego (symulowane wyżarzanie) lub łącząc części reguł w sposób analogiczny do rozmnażania płciowego (algorytmy genetyczne). Reguły są „wyraźne”: o ile rozumiemy nazewnictwo języka logicznego, w którym reguła jest napisana, możemy przynajmniej w zasadzie (w praktyce reguła może być dość złożona) zrozumieć jej wyprowadzenie. Istnieją inne potężne techniki, które można wykorzystać do kierowania naszą strategią, które nie pozwalają nam tak łatwo zrozumieć, dlaczego one pracują. To nie jest magia, choć czasami prawie jako taka się sprzedaje. Jednym z przykładów jest sieć neuronowa, która składa się z bardzo dużej liczby prostych, połączonych ze sobą jednostek, które mogą wykonywać funkcje logiczne. Zdolność tych sieci do wykonywania swoich zadań wynika z wysokiego stopnia łączności między nimi, co daje początek innej nazwie tej klasy technik: koneksjonizmowi. Zazwyczaj pojedynczy element w sieci neuronowej zachowuje się w sposób opisany na rysunku
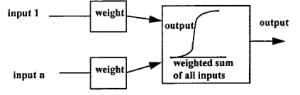
Do elementu neuronowego wprowadza się szereg wyjść innych elementów neuronowych, każdy poprzez element ważący, który zmienia siłę jego działania. Każdy element może mieć inną wagę. Następnie element neuronowy sumuje wszystkie te ważone dane wejściowe i daje wynik, który nie jest ich prostą sumą. W rzeczywistości ma kształt podobny do kształtu „S” pokazanego na rysunku. Ten kształt, który jest zbliżony do sposobu, w jaki zachowuje się neuron biologiczny w mózgu, bardzo słabo reaguje na małe sygnały wejściowe i ma tendencję do nasycania się dużymi. Oznacza to, że w procesach koneksjonistycznych, które tworzą sieć, bardzo małe jest ignorowane, a bardzo duże nie może nadmiernie dominować. Charakter połączenia pokazano na rysunku
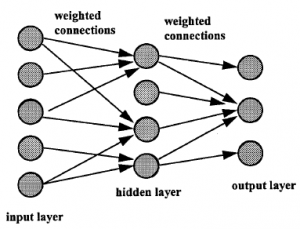
Neurony są ułożone w trzech warstwach: warstwa wejściowa, która otrzymuje dane do analizy, warstwa wyjściowa, która daje odpowiedź, na przykład rozpoznanie jednego obiektu wśród wielu, oraz warstwa ukryta. W typowym przykładzie OLAP moglibyśmy chcieć podzielić naszą bazę klientów na tych, którym warto zarządzać kontem, tych, do których należy po prostu wysłać wiadomość e-mail i tych, do których w ogóle nie warto się kontaktować. Mamy szereg przykładowych danych dla każdego z tych typów klientów. Nazywamy to „zestawem treningowym”. Tabela danych może być dość złożona: kod pocztowy, wiek, zawód itp. Każdy z tych wymiarów w tabeli danych jest arbitralnie przypisany do jednego z elementów wejściowych sieci. Nasz przykład będzie miał trzy neurony wyjściowe, nazwane następująco: 1 = „zarządzaj”, 2 = „poczta”, 3 = „ignoruj”. Zaczynamy od przypisania losowych wartości do wag sieci i wprowadzamy wartości pierwszego rekordu ze zbioru uczącego do warstwy wejściowej. Jest bardzo mało prawdopodobne, że spowoduje to, że tylko jeden węzeł wyjściowy będzie miał dużą wartość. Możliwe jest jednak zastosowanie prostego algorytmu, który po stwierdzeniu, że dane wejściowe odpowiadają typowi klienta, powiedzmy „1”, zmienia wagi w taki sposób, aby pierwsza wartość wyjściowa była większa, a pozostałe dwa mniejsze. wartości. Drugi przykład tej samej klasy obiektów jest stosowany do danych wejściowych i ponownie przeprowadzany jest proces dopasowywania wag. Ostatecznie wagi zbliżają się do stałej wartości, która w pewnym sensie jest zbiorową „pamięcią” typu 1. Możemy przechowywać wagi jako wzorzec rozpoznawania dla typu 1, a następnie powtórzyć proces z przykładami typu 2, a następnie dla typu 3. Tak więc, kiedy otrzymujemy dane o nowym kliencie, możemy to przetestować na trzech wzorcach i oczekiwać wysokiej wartości wyjściowej od tego, który najlepiej przewiduje preferencje zarządzania klienta. W przytoczonym przykładzie marketingowym sieć została przeszkolona na podstawie dostosowania wag według klasy, do której należał obiekt. W niektórych przypadkach możliwe jest nawet przeprowadzenie „treningu nienadzorowanego”: sieć spontanicznie zaczyna wyodrębniać różne grupy danych odpowiadające różnym klasom obiektów. Brzmi to dość magicznie, ale tak nie jest. Opiera się na tym, że dane z różnych klas obiektów mają właściwości dające się oddzielić. Różnice te mogą być bardzo trudne do dostrzeżenia dla ludzkich obserwatorów lub klasycznych metod statystycznych, ale muszą istnieć. W rzeczywistości jest to jeden z problemów z sieciami neuronowymi: wykrywają one różnice między różnymi klasami obiektów, ale nie zawsze można zobaczyć, dlaczego. Oznacza to, że generalnie nie można użyć sieci neuronowej do wyodrębnienia „cech”, które mogłyby być użyte za pomocą prostszych lub szybszych technik klasyfikacji; oznacza to również, że trudno jest przewidzieć, jak sieć, która poradziła sobie z jedną klasą problemów, poradzi sobie z inną. Sieci neuronowe zostały przyjęte entuzjastycznie po początkowym okresie sceptycyzmu; część (choć nie całość) tego sceptycyzmu powróciła w ostatnich latach.