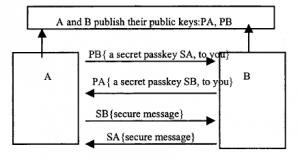
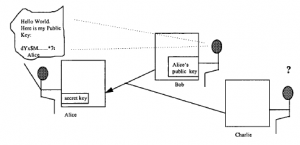
pierwszy rygorystycznie przeanalizowany podczas ostatniej wojny, w szczególności przez Claude’a Shannona z Bell Laboratories. Kiedy spotykamy się z tymi badaniami po raz pierwszy, może nas zaskoczyć, że nie były one skoncentrowane na tworzeniu coraz silniejszych szyfrów. W rzeczywistości głównym postępem, jaki dokonał Shannon, było udowodnienie, że chociaż istniał „doskonały” szyfr (w tym sensie, że nie można go złamać, pod warunkiem, że był wspierany przez silną implementację), w większości przypadków to wdrożenie byłoby niewykonalne. Ten doskonały szyfr znany jest pod różnymi nazwami, ale najczęściej jako jednorazowy pad. Według okazjonalnych doniesień publicznych, znajduje co najmniej jedno praktyczne zastosowanie – jako środek komunikacji między szpiegami a ich kontrolerami. Oto, koncepcyjnie, jak to jest używane:
Litery wiadomości (tekst jawny) są najpierw zamieniane na liczby: A = 1, B = 2 i tak dalej.
Więc; Sekretariat
staje się 19 5 3 18 5 20
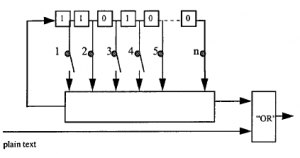
Agent szyfrujący posiada zestaw stron zawierających listy liczb z zakresu od 1 do 26, które zostały wygenerowane losowo: 21, 3, 13, 19, 5, 7 itd. Te z kolei są dodawane do liczb odpowiadających do tekstu jawnego. Jeśli suma przekracza 26, odejmuje się 26. Daje to zaszyfrowany tekst:
19 5 3 18 5 20
plus 21 3 13 19 5 7 daje
szyfrogram =14 8 16 11 10 27
Jeśli liczby zostały naprawdę wygenerowane losowo, nie ma możliwości, aby urządzenie przechwytujące mogło wrócić do tekstu jawnego. Jeśli jednak prawowity odbiorca ma kopię liczb losowych i wie, gdzie się zaczynają, łatwo jest je odjąć od zaszyfrowanego tekstu (a następnie dodać 26, jeśli wynik jest ujemny), aby wrócić do tekstu jawnego:
szyfrogram 14 8 16 11 10 27
minus 21 3 13 19 5 7 daje
tekst jawny 19 5 3 18 5 20
czyli SE C R E T
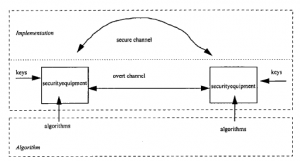
„Klucz” metody składa się z określonych liczb na podkładce; „krypto” to po prostu operacja dodania klucza do wiadomości. Chociaż jest to najbezpieczniejszy z możliwych system, jednorazowy pad ma poważny problem: rozmiar pada musi być taki sam, jak całkowita liczba znaków we wszystkich wiadomościach, które chcesz wysłać. Nie jest dobrym pomysłem ponowne użycie zestawu liczb: atakujący może połączyć inteligentne zgadywanie z dość prostymi statystykami, aby skutecznie złamać szyfr. To może nie być problem, gdy wiadomości, które chcemy wysłać, są krótkie i rzadkie. Kontroler i szpieg mogą prawdopodobnie umawiać się na wystarczająco częste spotkania, aby przekazać nowe jednorazowe podkładki. Jeśli jednak chcemy zapewnić wygodny mechanizm płatności międzybankowych, obejmujący miliony transakcji tygodniowo, trudno wyobrazić sobie wysyłanie kurierów po całym świecie z ryzami jednorazowych bloczków. Albo rozważmy przypadek próby zaszyfrowania programu telewizyjnego, aby mogli go oglądać tylko opłaceni widzowie: potrzebowalibyśmy jednorazowych padów zapewniających każdemu abonentowi telewizyjnemu kilka megabitów na sekundę.