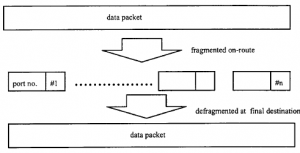
Ponieważ specjaliści ds. bezpieczeństwa są zbyt świadomi prawdziwości ostatniego akapitu, na ogół popierają podejście do bezpieczeństwa, które działa na wielu poziomach, z których technologia jest tylko jednym . Ważne jest, aby zacząć patrzeć na te kwestie od góry, a nie od dołu. Powszechnie wiadomo, że w celu zapewnienia, że funkcje zabezpieczeń spełniają to, co obiecują, należy kierować się rozsądną polityką bezpieczeństwa. Każda taka polityka powinna zaczynać się od przyjrzenia się zaangażowanym procesom biznesowym, zaczynając od oceny umiejętności, szkolenia i zaangażowania każdego zaangażowanego. W prawie wszystkich przypadkach będzie to zwykle przygnębiająco niskie (w przypadku zespołu atakującego może być odwrotnie) i każda implementacja zabezpieczeń musi to uwzględniać. Uzupełnieniem tej oceny powinna być również taka, która próbuje oszacować faktyczną wielkość strat materialnych w stosunku do kosztów ochrony. Ma to na celu nie tylko uniknięcie niepotrzebnych kosztów zakupu sprzętu; przedstawi również oszacowanie zakłóceń w pozostałej części operacji. Ogólnie rzecz biorąc, im większa ochrona zapewniana przez system bezpieczeństwa, tym większa niedogodność dla osób prawnie zaangażowanych. W związku z tym, jeśli Twój schemat bezpieczeństwa jest nieproporcjonalny do postrzeganego zagrożenia, możesz być pewien, że zostanie on naruszony przez użytkowników, którzy będą go traktować z pogardą. Istnieje tradycyjny argument za oddzieleniem operacji krytycznych od mniej krytycznych i stosowaniem tylko uciążliwych procedur bezpieczeństwa do tych pierwszych. W ten sposób łatwiej jest uzyskać akceptację procedur, ponieważ wszyscy zaangażowani widzą niebezpieczeństwa, a także zmniejsza rozmiar zadania. Jednak w operacjach komputerowych istnieje niebezpieczeństwo takiego podejścia. Nie zawsze łatwo jest dostrzec granicę między krytycznym a niekrytycznym. W dalszej części tego rozdziału przyjrzymy się atakom na procesy działające po drugiej stronie serwera sieci Web, po prostu wysyłając uszkodzone wiadomości HTTP do serwera sieci Web: atak przeskakuje z otwartego punktu dostępu do sieci na procesy wewnętrzne, które uważa się za prywatne. i chronione. Na koniec musisz również przeprowadzić ocenę ryzyka pod kątem prawdopodobieństwa ataku, przed i po wprowadzeniu jakiegokolwiek schematu bezpieczeństwa. Należy to mierzyć pod kątem wartości dla atakującego (nie tylko dla Twojej firmy) i zestawić to z prawdopodobieństwem posiadania przez atakującego niezbędnych umiejętności i dostępu. Te oceny bezpieczeństwa najlepiej pozostawić specjalistom ds. bezpieczeństwa, którzy są świadomi zarówno ludzkich słabości, jak i technologii. Tak więc bezpieczny system to nie tylko zestaw haseł i algorytmów szyfrowania. Obejmuje również codzienne procesy administrujące bezpieczeństwem: rolę help-desku w kontaktach z ludźmi, którzy „zapominają” swoje hasła, częstotliwość i dogłębność przeprowadzania audytów, rzeczywistość wiedzy, która atakujący mają na temat twojego systemu i niechlujnego sposobu, w jaki administrują nim twoi pracownicy. Chociaż zasady bezpieczeństwa handlowego nie powinny być uważane za prostą kopię zasad stosowanych w sytuacjach wojskowych, istnieją pewne ogólne wnioski, które wyciągnięto z tych ostatnich, które można zastosować w przypadku handlowym. Profesor Fredrich Bauer z Monachijskiego Instytutu Technologicznego zdefiniował zbiór maksym dla systemów kryptograficznych, które można również ogólnie zastosować do komercyjnego bezpieczeństwa komputerowego :
† „Wróg zna system” (znany również jako Maxim Shannona) – musisz założyć, że atakujący może mieć dostęp do projektu systemu (choć niekoniecznie do samego atakowanego systemu lub do określonych ustawień kluczy bezpieczeństwa). ). Nie tylko zasady, ale także często drobne szczegóły większości komercyjnych systemów szyfrowania i bezpieczeństwa systemu zostały opublikowane i są powszechnie znane. Wiele najlepiej znanych słabości i metod ataków będzie również dostępnych w domenie publicznej. Możesz oczekiwać, że atakujący będą co najmniej tak samo zaznajomieni z algorytmami i systemami operacyjnymi serwerów e-biznesu, jak większość personelu IT. Każdy algorytm musi być nie tylko sam w sobie mocny (trudny do złamania po nałożeniu określonego klucza), ale także wspierany przez proces, który zapewnia, że atakujący nie dostanie klucza w swoje ręce. Bezpieczne zarządzanie kluczami to jedna z bardzo dużych kwestii bezpieczeństwa.
† „Nie lekceważ przeciwnika” – nie bądź samozadowolony ze swoich systemów. Jak wspomnieliśmy, istnieje duża społeczność biegłych w obsłudze komputera hakerów-amatorów i zawodowych przestępców, niektórzy z dużą ilością pieniędzy i czasu w ich rękach. Istnieje również ogromna ilość wskazówek i procedur sondowania systemu dostępnych przez Internet. Na przykład, byłoby całkiem wykonalne, gdyby organizacja aktywistów przeprowadziła chiński atak loteryjny (patrz strona 249), w którym setka członków korzysta równolegle z nieprzerwanego oprogramowania, aby sondować Twoją witrynę przez 24 godziny na dobę, każdego dnia.
† „Tylko {ekspert ds. bezpieczeństwa}, jeśli ktokolwiek, może ocenić bezpieczeństwo systemu” – to nie jest praca dla amatorów. Musisz wykupić technologię i, w przypadku każdego stosunkowo skomplikowanego procesu biznesowego, zatrudnić usługi specjalisty ds. bezpieczeństwa. W rzeczywistości każdemu, ekspertowi lub innej osobie, bardzo trudno jest udowodnić siłę implementacji zabezpieczeń. To kolejny powód, dla którego musimy polegać na ograniczonej liczbie dostępnych na rynku algorytmów i ich implementacji. Chociaż później mogą się okazać, że będą miały słabe punkty, przynajmniej zostaną poddane obszernym testom, co w wielu przypadkach jest najlepszym, co możemy zrobić, aby udowodnić ich wartość. Być może najważniejszym atutem, jaki otrzymasz od akredytowanego konsultanta, jest to, że będzie wiedział, które systemy na rynku mają dobre wyniki w zakresie bezpieczeństwa. Ogólnie rzecz biorąc, lepiej kupować komponenty systemu, takie jak algorytmy szyfrowania, niż pisać własne. Nie wymyślaj ich!
† „Bezpieczeństwo musi obejmować ocenę naruszeń dyscypliny bezpieczeństwa” – dotyczy to zwłaszcza sytuacji handlowych; prawdziwe słabości często tkwią w niewłaściwym działaniu, jak na przykład w przypadku wspomnianych wcześniej kodów PIN do kart kredytowych. Najsilniejszy algorytm nie ma sensu, jeśli dzisiejszy klucz jest postnotowany na terminalu. Być może w kręgach wojskowych może to zostać uznane za przewinienie i tym samym zniechęcone, ale sprzedawcy eCommerce nie mogą tego zrobić swoim klientom. Podstawową zasadą środków bezpieczeństwa w handlu elektronicznym w handlu detalicznym musi być proces na tyle prosty, aby można go było zastosować w relacji klient-dostawca, bez konieczności szkolenia lub nadzwyczajnej staranności w imieniu klienta.
„Powierzchowne komplikacje mogą dawać fałszywe poczucie bezpieczeństwa” – dotyczy to szczególnie systemów komputerowych, gdzie złożoność może bardzo utrudnić audyt słabości systemu. Chociaż bezpieczeństwo wymaga ekspertów, eksperci odpowiedzialni za to w każdej konkretnej instalacji będą mieli żywotny interes w uwierzeniu, że to, co opracowali, jest nie do złamania. Nie wierz im i nalegaj na system, który może być kontrolowany przez stronę trzecią. Oprzyj się sugestiom pracowników, którzy nie są ekspertami ds. bezpieczeństwa, że mogą zainstalować dodatkowe funkcje własnego wynalazku.
Do listy profesora Bauera chcemy dodać kolejną, przygnębiającą maksymę:
† Skomplikowane systemy same w sobie stanowią zagrożenie dla bezpieczeństwa – a komputery są z natury systemami skomplikowanymi. Wrócimy do tego punktu później, ale jest to kwestia fundamentalna dla dalszych dyskusji, co stanie się jasne.