Kompleksowy e-biznes obejmuje nie tylko więcej procesów niż tylko zapewnienie eSklepu; niektóre z tych procesów mają również bardziej krytyczne właściwości. Możemy być gotowi wrócić do sklepu, który nie zawsze pokazywał nam wszystko, co ma na stanie. Być może moglibyśmy tolerować taki, który twierdził, że ma przedmioty, z których go nie było. Ale bylibyśmy znacznie mniej chętni do ponownego odwiedzenia takiej, która zabrała naszą kartę kredytową i nigdy jej nie zwróciła ani nie obciążała jej zakupami innych osób. Jest kilka zadań, które należy wykonać całkowicie i poprawnie. Techniczne środki do osiągnięcia tego to przetwarzanie transakcji. Często używamy terminu „transakcja” dość luźno, w znaczeniu interakcji między stronami lub systemami. W tej sekcji używamy jednak tego słowa w znacznie bardziej ograniczonym sensie, aby opisać interakcje, które mają dość specyficzne właściwości.
† Atomowość: transakcje mają miejsce lub nie mają miejsca – nie ma czegoś takiego jak transakcja częściowo zakończona. Jeśli transakcja nie została w pełni zrealizowana, oznacza to niepowodzenie, a wszystkie dane i stany zaangażowanych systemów muszą powrócić do swoich wartości, tak jakby transakcja nigdy się nie rozpoczęła.
† Spójność: ogólne „zasady” procesu, w którym odbywa się transakcja, w żadnym momencie nie powinny zostać naruszone – na przykład rachunki finansowe powinny być zbilansowane przed, po i w trakcie transakcji.
† Izolacja: transakcje są przeprowadzane niezależnie od siebie, nawet jeśli kilka odbywa się jednocześnie w tym samym środowisku. Implikacją tego jest zakazanie dwóm transakcjom jednoczesnego działania na tym samym fragmencie danych.
† Trwałość: po zakończeniu transakcji jej wpływ na dane i stany systemu powinien się utrzymywać – skutki transakcji powinny trwać dłużej niż czas trwania procesu transakcyjnego.
Patrząc w mniej abstrakcyjny sposób, warunki te muszą wydawać się oczywiście rozsądne: jeśli pieniądze są przekazywane z jednego konta na drugie, końcowym produktem musi być zmniejszenie jednego konta i zwiększenie drugiego (pomniejszone o wszelkie opłaty za usługę). Pieniądze nie powinny „opuszczać” jednego konta i nie docierać na drugie, na przykład z powodu awarii sieci. Transakcja audytu i równoważenia, która w połowie swojej operacji tymczasowo zamienia saldo dodatnie na moim koncie na saldo ujemne, nie powinna pozwolić transakcji obliczania kredytu w rachunku bieżącym na zobaczenie zmienionych danych i naliczenie odsetek od kredytu w rachunku bieżącym. Wreszcie, po dokonaniu przelewu na moje konto, nie spodziewałbym się, że przelew zniknie, ponieważ program przetwarzający przeszedł na coś innego. Przetwarzanie transakcji jest dość trudne i tak naprawdę nie podziela trybu kulturowego twórców stron internetowych: nie chodzi o szybki sukces przedsiębiorczy; chodzi raczej o konsekwentne zapobieganie niepowodzeniom. Na szczęście przetwarzanie transakcji ma długą historię w systemach mainframe, takich jak IBM CICS i gotowe rozwiązania kompatybilne z siecią WWW. Szczegóły dotyczące tych systemów są złożone, ale warto zapoznać się z niektórymi związanymi z nimi zasadami. Centralnym elementem operacji jest koncepcja menedżera transakcji, który współdziała z wieloma menedżerami zasobów.
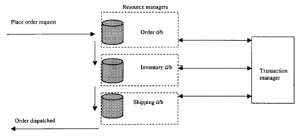
Rolą menedżera transakcji jest pełnienie roli centralnego punktu koordynującego szereg operacji bazodanowych związanych z transakcją. Współdziała z menedżerami zasobów, które są ochronnymi opakowaniami umieszczonymi wokół różnych baz danych. Gdy instancja transakcji jest tworzona (tj. gdy klient składa zamówienie), menedżer transakcji najpierw tworzy w pamięci zdefiniowaną przestrzeń dla tej konkretnej transakcji. Następnie kontaktuje się z odpowiednimi menedżerami zasobów, aby zwerbować ich do utworzenia instancji ich operacji na danych, które można prześledzić wstecz do tej konkretnej transakcji. Mówiąc dokładniej, rozważmy, w jaki sposób metody Enterprise JAVA JDBC pozwalają nam obsłużyć transakcję składającą się z wielu operacji na bazie danych. Załóżmy na przykład, że chcemy przyjąć zamówienie na niektóre towary, pod warunkiem, że kontrola kredytowa potwierdziła, że klient ma środki.
† W przypadku prostej operacji JDBC za każdym razem, gdy wykonujemy operację na bazie danych, ta pojedyncza operacja jest uważana za transakcję. Linia kodu odpowiadająca „umieszczeniu adresu klienta w bazie danych wysyłkowych” doprowadziłaby natychmiast do tego. Proces odpowiedzialny za wysyłkę towaru, który przebiega asynchronicznie, umieściłby więc tę pozycję na liście do wysłania – czego nie chcemy, aby działo się to automatycznie.
† Musimy więc wyłączyć automatyczną zmianę danych w bazie danych. Robimy to za pomocą prostej instrukcji, która wyłącza funkcję „autocommit” w poleceniach JDBC. Odbywa się to za pomocą wiersza kodu, który zawiera oświadczenie: „.setAutoCommit(false)”. Zasadniczo zmiana w bazie danych jest zawieszona. Prawdopodobnie chcemy również zrobić podobną rzecz z fakturą rozliczeniową dla naszego klienta. W ten sposób wszystkie polecenia bazy danych w określonym bloku kodu mogą być trzymane w napięciu.
† Teraz otrzymujemy wiadomość zwrotną z bazy danych o kredytach mówiącą, że kredyt X jest dobry. Następnie reaktywujemy żądania do odpowiednich baz danych.
† Ale jeszcze nie skończyliśmy; wiele innych rzeczy może pójść nie tak: na przykład wpis danych może być błędny lub tymczasowo niedostępny. Po pierwsze, wszystkie bazy danych muszą zwrócić komunikat, że mogą skutecznie zmienić dane w zadowalający sposób. Dopiero gdy to zrobią, komenda „.commit” otrzyma flagę „prawda”, która sygnalizuje wszystkim bazom danych, że można bezpiecznie kontynuować zmianę danych. Polecenie również następnie zwalnia wszelkie blokady, które wymusili wobec innych procesów, które chciały uzyskać dostęp do tych samych danych. Proces ten jest znany jako zobowiązanie dwufazowe i jest podstawowym elementem przetwarzania transakcji.
† Ale załóżmy, że coś pójdzie nie tak: kredyt jest zły lub baza danych przewróciła się: w tym przypadku flaga to „false”, a program wydaje polecenie „.rollback”, które przerywa transakcję, pozostawia dane we wszystkich bazy danych bez zmian i usuwa wszelkie blokady danych. Rzeczy wracają dokładnie do tego, czym były przed próbą transakcji.